

How to implement agentic AI in your organization? More companies now treat this question like a board-level instead of an experiment. Businesses are moving past basic chatbots and starting to deploy AI agents that can plan tasks, call tools, update systems, and provide reports. At the same time, executives are under pressure to prove value, control risk, and comply with emerging AI regulations.
Adoption is no longer the blocker. According to McKinsey’s State of AI research, more than 70% of organizations now report regular use of generative AI in at least one business function, with adoption rising sharply over the past year. The conversation has shifted accordingly: the question is no longer “should we experiment with agents?” but rather “how do we operationalize agentic AI, safely, with clear ownership, and at scale?”
Regulation is also here. The EU AI Act, in force since 2024, establishes governance requirements for high-risk AI systems and sets penalties that can reach EUR 35 million or 7% of worldwide annual turnover for certain violations. These obligations are concrete: if you deploy an AI system that takes actions affecting people, money, or regulated data, you will be expected to demonstrate how it works, what data it uses, how decisions are controlled, and where that data resides. In particular, regulated data, such as protected health information (PHI) or financial records, must remain within approved regions and environments and must not be sent to public model endpoints.
This article defines what agentic AI actually is (and what it is not), outlines the technical foundations required before deployment, explains how to integrate agents into real business workflows, and walks through a phased roadmap from pilot to scale, concluding with concrete risk and governance practices. We assume agents operate within an orchestration runtime that plans steps, enforces policies, and executes approved tool calls rather than allowing a base LLM to act autonomously; that audit trails are immutable or tamper-evident; that timeouts, circuit breakers, and real-time spend monitors prevent runaway loops and excessive API costs; and that every model, prompt, or tool change passes automated evaluations and regression gates before rollout. The goal is simple: build and deploy value-generating agentic AI with guardrails, observability, and accountability built in.
What Is Agentic AI?
Most AI systems today fall into one of three buckets: a chatbot answers questions; a copilot assists a human by drafting, suggesting, or summarizing; an agent can pursue a goal.
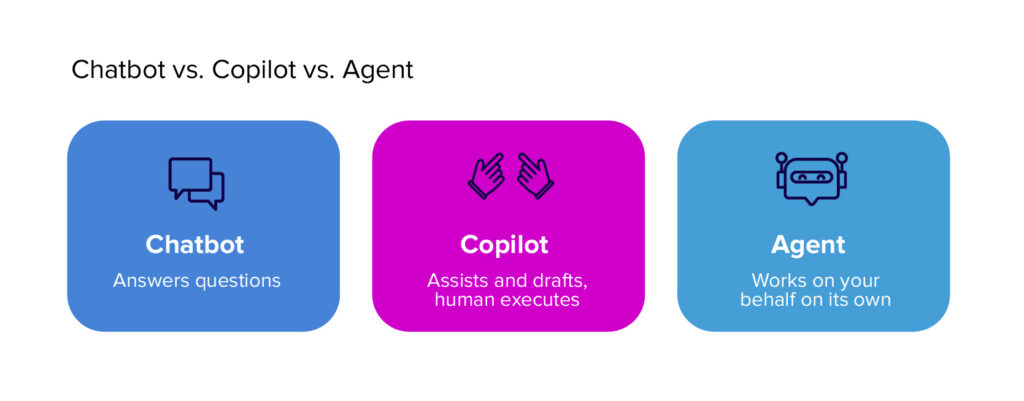
Agentic AI refers to AI systems that take action. An agent can interpret an objective, “reconcile these invoices,” “update this supplier record”, break it into steps, invoke tools or APIs to execute those steps, and report results. Instead of waiting for a human to ask every follow-up question or click every button, the agent plans, performs, and documents progress.
This is possible due to modern large language models (LLMs) that now expose structured tool use (sometimes called function calling) where the model can request a specific action in a controlled way. OpenAI documents this pattern as a tool calling in its API. Anthropic’s Claude supports tool and computer use, which enables the model to operate within software environments in a supervised and auditable manner. Google’s Gemini 1.5 models feature extremely long context windows (up to 1 million+ tokens, as reported publicly, with 2 million tokens in some preview tiers), allowing an agent to reason over large amounts of system knowledge, logs, or case history in a single session.
That combination (planning, tool use, and long context) is what separates an AI agent from a chatbot. A chatbot can draft an email. An agent can draft the email, open your ticketing system, file the case with the correct metadata, update the affected record, notify the account owner, and then summarize their actions. And it can do that repeatedly without having to start from zero every time.
There’s another critical element to AI agents: memory. Traditional assistants operate in short-lived interactions. Agents are expected to maintain state across steps and sometimes across sessions. That state might include the status of an open task, a supplier’s escalation history, or which policy version was in force when a decision was made.
What Infrastructure Do You Need to Implement Agentic AI?
Before you implement agentic AI in your organization, you need to make sure the foundation can actually support it. Yeah, tricky. Why? As established, an AI agent goes beyond just a model to actually plan, call tools, touch production data, leave audit trails, and more. Within this framework, you need to think about five layers: compute, data, observability, security, and memory.
Compute: Can you reliably run and scale the agent?
Agentic AI is stateful and interactive. It may retrieve context, reason through a plan, call an API, check the result, call another API, summarize the outcome, and log everything it did. That is multiple inference calls plus orchestration logic. From an infrastructure point of view, that means you need:
- Elastic compute for inference. You need to scale up when task volume spikes, but also scale down when traffic is low. Cloud providers are actively investing in AI-optimized compute (GPUs, TPUs, inference-optimized instances) because enterprise AI workloads are growing fast. NVIDIA, for example, reported tens of billions of dollars in quarterly data center revenue driven by AI demand, which reflects how much capacity organizations are standing up to run and serve models in production.
- Low-latency paths for actions that happen in the loop of a user workflow (for example, an agent assisting a support analyst live).
- Batch/queue paths for longer-running or non-urgent agent work (for example, nightly reconciliation, report generation, claims packaging). This keeps the real-time experience snappy and moves heavy lifting to controlled windows.
Practically, you want an execution environment that supports autoscaling, timeouts, concurrency limits, and isolation by tenant or business unit.
Data: Can the agent access what it needs without overexposing what it shouldn’t?
Agentic AI is only useful if it can act on relevant information. That usually means giving it access to operational data, not just public knowledge. In practice, that requires four pieces:
- A governed source of truth. The agent needs access to accurate, up-to-date data about customers, cases, orders, assets, inventory, or patients. Usually, that lives in a data warehouse or data lake and in line-of-business systems.
- Fresh signals. For certain actions (routing an urgent escalation, reassigning a support case), the agent can’t work off last week’s snapshot. You need some form of event stream or message bus so it can react to new events rather than stale data.
- Retrieval and semantic search. Most production-grade agents use Retrieval-Augmented Generation (RAG). Instead of trusting whatever the model remembers, they pull relevant internal documents or records at runtime, then ground their answer in that context. This pattern is documented by major providers as the standard way to reduce hallucinations and keep answers aligned.
- Access control and data minimization. Disclaimer: You can’t just dump everything into the agent and hope for the best. The EU AI Act categorizes certain AI systems as high-risk. It requires strict control over training data, decision logic, and auditability, with penalties that can reach € 35 million or 7% of the global annual turnover for certain violations. That means you need to enforce which data an agent is allowed to retrieve for a specific request, and you need a record of what it saw and why.
Observability: Can you see what the agent did?
If you cannot explain what the agent did, you cannot defend it to security, audit, legal, or a regulator. For every run, you should be able to answer the following questions:
- What was the user request or trigger?
- What plan did the agent generate?
- Which tools / APIs did it call, in what order, with what parameters?
- What data did it retrieve?
- What response did it return?
- Did it escalate to a human, and if so, who approved what?
Modern monitoring stacks are starting to formalize this. Vendors like Datadog now advertise LLM observability features that include request traces, tool invocation timelines, latency, cost per request, token usage, and policy/safety checks for agent chains. This reflects a shift toward treating AI agents the same way we treat microservices: instrumented, auditable, metered, and continuously evaluated.
This is aligned with the NIST AI Risk Management Framework (AI RMF), which defines AI governance as an ongoing cycle of:
GOVERN → MAP → MEASURE → MANAGE
NIST explicitly recommends continuous monitoring, documentation of behavior, and defined escalation procedures for AI systems that affect business processes.
Security: Can you trust the agent with tools?
An agent becomes dangerous the minute it is allowed to call tools. In a typical agentic AI implementation, the model can do the following:
- Create or update a record in a CRM
- Submit a request in an ERP
- Generate a ticket in a support platform
- Draft and send an email
- Initiate a handoff in a care management platform
- Trigger a diagnostic step in a production system
That means:
- Every tool or connector must be permission-scoped (“this agent can only create draft tickets in this queue”).
- Credentials must be short-lived or just-in-time, not permanent static tokens.
- High-impact actions must require human approval.
- Every action must be logged and attributable.
This is exactly the risk class OWASP calls excessive agency and insecure plugin design: agents (or plugins) with broad, ungoverned permissions can be driven, even indirectly, into taking actions you didn’t authorize. OWASP’s recommendations align directly with the principles of least privilege, human-in-the-loop oversight for high-risk actions, and policy validation before execution. Learn more about OWASP vulnerabilities.
Google’s Secure AI Framework (SAIF) formalizes similar principles from a platform angle: identity and access control, data protection, supply chain integrity, and continuous monitoring as first-class security controls for AI systems.
Memory: When should you implement agentic memory in AI?
This is a critical decision point in agentic AI implementation that most teams underestimate. Memory sounds powerful: “The agent remembers the case, understands our policies, and knows the history with this vendor.” But persistent memory is also a liability if it’s not governed. So, you should not default to letting the agent remember everything forever. You should be intentional about what kind of memory you enable and when.
There are four practical forms of memory you will likely need to consider:
- Working memory (short-term task state). This is what the agent needs to finish the current workflow: ticket context, current step, partial draft, and who’s assigned. This can often live in the agent’s orchestration layer or session store.
- Reference memory (domain or policy knowledge). Instead of hardcoding rules into the model, you can store structured SOPs, compliance rules, escalation paths, or product info and let the agent look them up. This is often implemented as retrieval, not as a writeable brain. It’s easier to govern and audit because you control the source.
- Episodic memory (what actually happened). This is an execution log: what the agent did, when, with which tools, and who approved. This is essential for audit and explainability, especially under regulatory pressure. Also, episodic memory is not optional if the agent has the authority to act.
- Long-term personalized/organizational memory. This is where you let the agent learn preferences over time: for example, “this care team needs discharge summaries in a particular format.” This type of memory has the highest governance requirements:
- You must control what gets written (filter toxic or injected content).
- You must version it.
- You must be able to erase it on request (privacy, contractual obligations, right to be forgotten).
- You must be able to prove how it influenced a decision if challenged.
How to Integrate Agentic AI Into Real Workflows (Without Wreaking Havoc)
Once you have the foundation in place, the next challenge is integration: how does the agent actually act inside your organization? This is usually where projects stall. Five integration principles matter:
Prefer API-level integration over UI scraping
You get two basic choices when you ask an AI agent to do something in an internal system:
- Call an API or service endpoint (for example, POST /create_ticket, PATCH /supplier_status).
- Drive the UI like a bot (click, type, navigate).
Option 2 looks attractive because it feels fast. But it’s brittle, hard to audit, and almost impossible to govern. A layout change can break your process. A permissions change might go unnoticed. You also have less granular control over what fields the agent is allowed to touch.
Option 1 is what you want in production. It’s more predictable, testable, and auditable. It supports least privilege, because you can expose only the operations you’re willing to let the agent perform. This is the same design pattern that powers tool calling/function calling in modern LLM platforms.
Wrap each capability as a microservice-style tool with least privilege
Do not give the agent direct access to your systems with full credentials. Instead, create a thin tool service around each permitted operation. For example:
- create_support_ticket service
- update_purchase_order_status service
- generate_discharge_summary_draft service
- request_supplier_escalation service
Each of those services should:
- Accept only the parameters it actually needs
- Enforce validation and business rules
- Use its own scoped credentials (not the agent’s global superuser key)
- Log every call in a way you can audit later
The benefit for you: if something goes wrong, you can shut off one tool service without disabling the entire agent.
Use events and queues to decouple the agent from core systems
One of the biggest mistakes teams make is letting the agent call production systems synchronously for everything, in-line, in real time. That couples your agent tightly to every service it touches.
A cleaner approach is event-driven integration:
- The agent proposes an action (“open a new quality incident”).
- That action is placed in a queue, topic, or workflow system (for example, Kafka, pub/sub, SQS, or your internal workflow orchestrator).
- A downstream service with clear ownership performs the change, validates it, and writes back the result.
This gives you:
- Retry logic, backpressure, and isolation (if the downstream is slow or down, your agent doesn’t fall apart).
- Natural logging (“this exact request was emitted at this exact time”).
- An approval step, if needed (e.g., a human supervisor can review queue messages above a certain risk threshold).
This is also how you keep operations and compliance comfortable. You’re not saying the AI did whatever it wanted in the ERP. You’re saying the AI generated an actionable work item, which moved through our governed workflow like any other change.
Keep the source of truth systems authoritative
This part sounds boring, but it decides whether the rollout actually sticks. If the agent creates or updates something, that action has to land in your system of record. You cannot afford shadow systems where the AI version of reality drifts from the official version of reality.
There are two implications here:
- The tool services we just described must write results back into the system of record in a controlled, auditable way.
- The observability layer needs to capture that mapping: request → tool call → system update → final state.
Why? Because the moment leadership sees agentic AI, they’ll ask for impact.
- Did it reduce case handling time?
- Did it improve first-time resolution?
- Did it reduce production downtime?
- Did it shorten order cycle time?
You cannot answer those questions if the data is scattered. You answer them by having every agent's decision mirrored back into the systems the business already uses.
Log everything (for audit, compliance, and trust)
Every agent-initiated action should generate structured, reviewable evidence:
- What triggered it
- What data was accessed or retrieved
- Which tool(s) were called, with what parameters
- Whether a human approved a sensitive step
- What was ultimately changed in the system of record
- When and by whom
This protects you in three ways:
- Operationally, debugging and incident response are actually possible.
- Financially, you can track cost per task, time saved, and escalation rate instead of arguing about ROI feelings.
- Regulatorily, you have an audit trail.
From Pilot to Scale: The Agentic AI Roadmap
You should not turn on an AI agent for the whole company. You implement agentic AI in controlled phases, and you only graduate to the next phase once the previous one is behaving, measurable, and governable.
A good roadmap has three stages: Pilot → Deployment → Scale. Each stage has gates. If you can’t clear the gate, you don’t move forward.
Phase 1. Pilot (prove value in a safe slice)
Goal of this phase: Prove that an agent can deliver real, measurable value on one workflow, without breaking anything, leaking anything, or confusing people. How to structure the pilot:
- Pick one process, not ten. Think: “triage low-priority support tickets,” or “prepare claim documentation drafts.”
- Define 2–3 concrete success metrics before you start:
- Time per task (how long does this take today vs. with the agent?)
- Human escalation rate (how often does a person need to step in?)
- Cost per task (including model inference cost and any new infra cost)
- Keep a human in the loop. The agent can propose, draft, assemble, or recommend, but a human still approves any action that changes records, touches money, or affects a customer or patient.
What you need in the pilot:
- A sandboxed version of each tool that the agent can call.
- Logging and observability running from day one. If you cannot trace what the agent did (inputs, plan, tool calls, outputs), you are not ready to move past pilot.
- An explicit rollback plan: “If performance drops below X or we see unsafe behavior Y, we revert to manual.”
Your exit gate from pilot:
- The agent performs the chosen workflow reliably.
- The numbers are better than baseline (for example, handling time dropped 30%, escalation rate stayed under 15%, per-task cost is stable or lower).
- No red flags in audit logs, privacy, or security.
Phase 2. Deployment (run it in production, with accountability)
Goal of this phase: Move the agent from a safe sandbox to a real operational environment for that same workflow, and make it part of how work actually gets done.
What changes in deployment:
- The agent is now allowed to act in production (within strict permissions).
- Human approvers shift from always approving everything to approving when risk > threshold.
- Business owners, not just the AI team, start to rely on agent output.
To make that viable, you need three things:
- Runbooks and escalation paths. You need documented answers to:
- What happens if the agent stalls or loops?
- What happens if the agent asks for permission they shouldn’t have?
- Who gets paged if something fails after business hours? This matters because once an AI agent sits in the middle of an operational process, it becomes part of your incident surface.
- Change management and training. A common failure is that AI pilots look impressive, but frontline teams don’t adopt them because the workflow, incentives, or handoff are unclear.
- Compliance alignment. By this point, legal, security, and audit will want proof that the system is under control. That means:
- You must log every meaningful action the agent takes, who approved it, and what data it accessed.
- You must be able to reconstruct why an agent behaved the way it did
- You must restrict access to sensitive or regulated data to approved use cases.
Your exit gate from deployment:
- The workflow is running in production conditions, with measured KPIs.
- You have a documented runbook and escalation path.
- Stakeholders outside of the AI team (operations, compliance, line-of-business owners) accept the agent’s role and process impact.
- You can defend the system’s behavior to audit if asked.
Phase 3. Scale (expand to adjacent workflows safely)
Goal of this phase: Roll the agent pattern out to more workflows, more regions, or more departments, without losing control. Scaling means: repeatably cloning what just worked, while improving governance. To scale safely, you need to formalize four capabilities:
- Multi-workflow orchestration and load management. You’re no longer handling one task at a time. You’re handling multiple classes of tasks, possibly in parallel, possibly across time zones. You need concurrency limits, rate limiting, preemptive throttling, and graceful degradation.
- Regression testing for safety and quality. Before you add a new workflow, you should be able to run automated evaluations that check:
- factual accuracy/groundedness,
- privacy adherence,
- policy compliance,
- tool usage safety,
- cost/latency behavior under load.
- Continuous evaluation is emerging as the best practice across responsible AI programs. The UK AI Safety Institute, for example, has released open testing frameworks like Inspect to evaluate model and agent behavior on complex tasks, tool use, and safety under adversarial conditions.
- Controlled memory strategy. At scale, memory becomes critical and risky.
- You’ll want working memory (task state), episodic memory (what happened: actions, timestamps, approvals), and governed policy/reference memory (standard operating procedures, escalation rules).
- You should not enable persistent long-term memory across individuals, accounts, or patient records unless you have:
- access control
- retention and deletion policies
- auditability of who wrote what and why
- Cost governance and ROI model. By this point, leadership will ask: “Is this paying for itself?” You should be tracking:
- Time saved per task vs. baseline
- Error/rework rate
- Human escalation rate
- Cost per task (model inference, infrastructure, maintenance)
- Ticket volume absorbed or cycle time reduced
Your exit gate from scale:
- The pattern is repeatable.
- You can introduce a new workflow following the same process.
- You can prove value in terms of hours saved, incidents reduced, or throughput increased, and you can do it in a way that stands up to legal, audit, and exec review.
How to Mitigate Risk When You Deploy Agentic AI
Once an AI agent can take action, not just answer questions, you’re no longer dealing with chat. You’re dealing with operational automation. At that point, risk management becomes part of the implementation itself. There are five categories you need to get right: action safety, access control, memory governance, reliability, and accountability.
Keep the agent on a leash: require controlled actions, not blind autonomy
Agentic AI systems can plan tasks and call tools, but that doesn’t mean they should be allowed to freely update production systems. You need to enforce approve or simulate first, execute second, especially for actions that affect money, compliance, safety, or regulated data. In practice:
- High-impact calls (for example, issuing a credit, closing a case, escalating a supplier, signing off on a discharge summary) should require explicit human approval.
- Lower-impact calls (for example, drafting a ticket, summarizing a case, generating a compliance packet) can run automatically.
Enforce least privilege on every tool, connector, and integration
Your agent should not hold broad, persistent credentials to production systems. Each callable tool or service should have:
- Its own narrow scope (“can create draft tickets in Queue B,” not “can edit anything in Support”)
- Short-lived credentials or just-in-time tokens
- Rate limits and per-tenant throttles
- Detailed logs
Govern memory like regulated data, because it is
Teams love the idea that the agent remembers context. Teams also underestimate the liability. There are four kinds of memory you may consider:
- Working memory: current task state.
- Reference memory: policies, SOPs, standard language.
- Episodic memory: what actually happened (actions, timestamps, who approved).
- Long-term memory: durable preferences and historical details tied to customers, suppliers, patients, etc.
Before you allow long-term memory:
- Add DLP/redaction in front of anything that will be persisted, so you’re not storing sensitive data or injecting malicious instructions unfiltered.
- Version memory entries so you can roll back what the agent believes.
- Attach access control and retention rules (for example, records involving personal health information cannot persist beyond X days unless explicitly approved).
Engineer reliability: timeouts, retries, and graceful failure
In demos, the agent always succeeds. In production, systems go down, APIs stall, rate limits trigger, or context gets messy.
Your orchestration layer should:
- Use timeouts and circuit breakers so the agent doesn’t retry forever or spiral into a tool call loop.
- Queue non-urgent tasks instead of forcing everything to run synchronously.
- Write safe fallbacks (“I couldn’t complete X, here’s what I attempted, here’s what you should do next”) rather than silently failing.
Instrument everything (and treat logs as evidence)
If the agent is touching production systems, you need a full audit trail: input, plan, tool calls, output, approvals, and results. That supports:
- Debugging and incident response,
- Compliance posture,
- ROI reporting.
How Svitla Systems Fits into Risk Mitigation
There’s a pattern here. None of these controls, least-privilege tool wrappers, audit-grade logging, policy-gated actions, governed memory, approval workflows, is flashy. They’re engineering. They’re what turns an AI demo into production-grade, defensible automation.
This is exactly where Svitla Systems partners with clients:
- Designing pilots with scoped workflows and measurable outcomes,
- Building secure integration services, the agent is allowed to call (and only those),
- Implementing observability so every agent action is traceable and attributable,
- Standing up memory governance and retention rules that align with NIST AI RMF and with regulatory expectations like the EU AI Act.
The companies that succeed with agentic AI do not start by wiring an autonomous agent into their ERP and hoping for the best. They start with one workflow. They define success metrics. They put a human in the loop for high-risk steps. They build the right integration surfaces so the agent can act in controlled ways. They log everything. They prove value. Then, and only then, they scale.
This is where Svitla Systems fits. We partner with teams to:
- Identify the first workflow that’s safe and worth automating,
- Build the secure microservices and connectors that the agent is allowed to call (and nothing more),
- Stand up observability so you can trace what the agent did and prove ROI,
- Implement governance aligned with frameworks as an ongoing cycle.
The result is not just an agent that can act. It’s an agent you can defend to your CFO, your CISO, and, if needed, a regulator. That’s what “production-ready” looks like in 2025.
Let’s get you ready for what’s next.


