

In Jonathan Swift’s Gulliver’s Travels, giant Gulliver was defeated by tiny Lilliputians. Even though they were small, due to their planning and synchronized activities, they successfully defeated the giant. This is a perfect metaphor for modern software construction. Developing an application was like being Gulliver, as a lot had to be managed in terms of complex, weighty infrastructure, e.g., server provisioning, planning for capacity, and keeping everything up and running.
But today, with serverless architecture, the playing field has changed. Like the Lilliputians, tiny, thin scripts can be incredibly powerful when linked together as a system. Rather than focusing on servers, developers can concentrate on writing the essential logic, linking components together, and delegating the heavy lifting to cloud services.
This post presents a sample in-the-wild example, a Beatport Chart Playlist App, to demonstrate how serverless tools in AWS enable the development of a product, from idea to launch, without ever requiring a server.
Real-World Use Case: Beatport Chart Playlist App
I love music. I can’t imagine my day without that. Back in our childhood, we used to trade cassettes to get new music. Discovered new songs from TV, radio charts, etc. However, nowadays, things have become much easier. We all have access to various music platforms (YouTube Music, Apple Music, Spotify, etc.), where almost any music is available. The thing I’m struggling with is getting new music into my collection. I use the Beatport chart to discover new popular electronic music, and then I search for it on YouTube. I’m too lazy, though, to do that manually. That’s tedious, so I automated that.
Let’s take a look at the architecture. This is a music chart processing automated system that web-scrapes Beatport data, sends the scraped data to a server for completion with information pulled from YouTube Music, and then automatically produces public YouTube playlists. The automated system is developed based on an event-driven AWS serverless architecture.
What Is Beatport?
Beatport is one of the world’s largest charts for DJs, producers, and electronic music geeks (looks like I'm the last one). It allows you to purchase high-ranked tracks across various genres, including house, techno, drum & bass, and trance, with daily and weekly charts that reflect trends within the global electronic music community. DJs often use these charts as a source to find out about new releases and what’s hot in clubs and festivals.
What Is Serverless Architecture?
Technically speaking, serverless is not the same as “no server.” There are still servers, but server management falls exclusively on the cloud provider. You don’t have to write complicated code: only functions and service linking.
On the other hand, conventional methods based on EC2 instances or even containers imply continuous infrastructure upkeep. Serverless eliminates that chore and allows fast prototyping and production-ready apps.
Core elements:
- Event-driven. Function execution is triggered by events such as API calls, file uploads, or schedules
- Auto-scaling.Automatic adjustment of capacity based on workload
- Pay-as-you-go. You pay only for the actual execution time
- No server management. No patching, scaling groups, or manual deployments
Typical Serverless Architecture on AWS
AWS provides a complete ecosystem for building serverless systems. Imagine it as a miniature city, with every service a specialized guild or district:
- API Gateway or App Runner, the city gate. Where travelers (clients) enter, requests are inspected and routed to the right street.
- AWS Lambda, the guild of artisans.AWS Lambda forms the heart of our Lilliputian workforce: a guild of agile craftsmen that show up only when invoked. These artisans are assigned specific tasks, complete them efficiently, and then disappear once their job is finished. In real-world terms, it allows developers to run code without provisioning or managing servers. Lambda scales automatically and charges only for the compute time used. This makes it perfect for event-driven workloads, where small and well-defined functions handle data processing, API requests, and automation with minimal overhead.
- EventBridge, the clocktower.The scheduler that chimes on time, retries missed beats, and records every strike in the chronicles.
- S3, the granary & archives.Where each day’s harvest (raw chart data) is neatly stored, versioned, and aged into cheaper cellars.
- DynamoDB, the registry hall. Every track is a citizen with a unique ID. Updates enrich records, no duplicates, no chaos.
- Athena, the great library. Think of Athena as the Great Library of our Lilliputian city: a vast reading hall where scholars can open any scroll (JSON file) stored in the Archives (S3) and ask questions in the universal language of SQL. With Athena, there’s no need for complex ETL pipelines or separate databases; the data remains where it was collected, yet becomes instantly searchable. You can analyze historical charts, compare weekly movements, or identify artists that consistently appear in top positions, all without moving data or maintaining additional infrastructure.
- CloudWatch, the watchtowers.Sentries observing the city: metrics, logs, and alarms across every guild.
This ecosystem is elastic, cost-efficient, and self-maintaining, where each service is a specialist contributing to a seamless system.
Data Flow
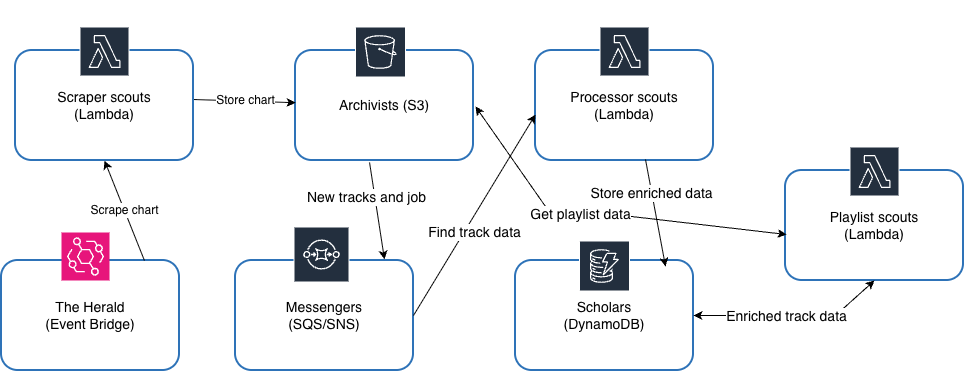
In our Lilliputian city, the data journey resembles the work of many coordinated guilds:
- The scraper scouts (Lambda). At dawn each week, the scouts venture to Beatport to collect the newest Top 100 tracks and return with the harvest of data.
- The archivists (S3). They carefully store every harvest in well-labeled baskets - JSON files organized by date, preserving both current and historical charts.
- The messengers (SQS/SNS). Once the harvest is complete, agile couriers carry the news across the city so that other guilds know it’s time to act.
- The processor scouts (Lambda). Upon receiving the news from messengers. They start looking for the new track on the streaming service.
- The scholars (DynamoDB). Inside the Registry Hall, scholars catalog each track as a new citizen, verifying whether it already exists and enriching it with new details from YouTube.
- The herald (EventBridge). When the last record is written and the charts are ready, the Herald rings the Clocktower bell, signaling the Playlist Guild to publish a new YouTube playlist for the people.
Through this network of tiny but skilled citizens, data flows seamlessly, from discovery to publication, without a single human having to manage a server.
S3, The Granary of Chart Data
Amazon S3 serves as the primary storage layer for raw chart data in our music processing pipeline. It provides a cost-effective, reliable, and scalable solution for storing JSON snapshots of scraped music charts, making them available for both real-time processing and future analytics through services like Amazon Athena.
Why use S3 for Chart Data Storage
S3 is ideal for this use case because:
- Cost-effective. Pay only for what you use, and automatically move unused data backward
- Reliable. 99.999999999% (11 9's) durability ensures data won't be lost
- Analytics-ready. Direct integration with Athena, QuickSight, and other AWS analytics services
- Event-driven. Native S3 events trigger downstream processing automatically
Data Structure and Organization
Our chart data follows a hierarchical structure that enables efficient querying and lifecycle management:
charts-vibe-playlists/
├── beatport/
│ ├── 2025/
│ │ ├── 08/
│ │ │ ├── 30/
│ │ │ │ └── top100-120000.json
│ │ │ └── 31/
│ │ │ └── top100-121500.json
│ │ └── 09/
│ │ └── 01/
│ │ └── top100-123000.json
The BeatportScraperFunction is responsible for collecting chart data and storing it in S3. When new files arrive in our bucket, with the help of S3 events, our workflow proceeds, triggering the next artisan to perform their task.
We add a lifecycle policy that moves data to IA/Glacier in 30/60… days and removes objects in 365 days (this is an example).
Benefits for Analytics
This S3-based approach enables powerful analytics capabilities:
- Historical analysis. Track the chart evolution over time
- Athena queries. SQL-based analysis without data movement
- Cost optimization. Automatic lifecycle policies move old data to cheaper storage classes
- Data Lake integration. Easy integration with other AWS analytics services
The stored JSON files serve as both the trigger for real-time processing and a historical record for future analysis, making S3 the perfect foundation for our music chart processing pipeline.
EventBridge, The Clocktower
EventBridge is a serverless event bus that makes it easy to connect applications using data from your own apps, integrated Software-as-a-Service (SaaS) applications, and AWS services. The solution utilizes it as a powerful and reliable scheduler to periodically trigger the BeatportScraperFunction.
Why would I even use EventBridge over a simple cron job?
You could certainly use a cron job running on an EC2 instance (you should have an EC2 instance, though) or even a Lambda artisan (easier, but it requires workarounds) – EventBridge offers several advantages for cloud-native applications:
Centralized management. Your scheduled rules are all in one place, defined as infrastructure-as-code right in our template.yaml. This makes them easily traceable, versioned, and managed.
Enhanced reliability & retries. EventBridge has built-in retry policies with exponential backoff. The failure of the target Lambda function, or its throttling, will be automatically retried by EventBridge, enhancing the resilience of our scraping process. So, if the Beatport website is down when our scouts go for the weekly hunt, they would wait till the mammoth comes back.
Deep integration & logging. It integrates well with AWS services. Every invocation attempt will be logged in CloudWatch; rest assured that your scheduled tasks ran, when they ran, and whether they succeeded. The tale of the great quest won’t be forgotten.
Decoupling. The scheduler, EventBridge, has no linkage with the artisan, Lambda. We can modify the schedule without changing the Lambda code or logging into an EC2 instance to reschedule. We could even route the same schedule to multiple squads.
DynamoDB, The Registry Hall
At the heart of our system lies Amazon DynamoDB, the single source of truth for every track. A highly performant and scalable NoSQL database ensures data integrity and enables powerful features.
Why DynamoDB?
We chose DynamoDB for several key reasons that are critical to our application:
- Fast, predictable lookups. The main challenge is how to identify whether we’ve previously seen a particular track quickly. Instead of scanning the entire database for every incoming track (that could be pretty costly), we create a deterministic `track_id` as the partition key by hashing the track’s title and artist and updated_at as a sort key. This way, we can utilize the GetItem operation provided by DynamoDB, which provides access directly to a specified item. This is the cornerstone of our deduplication strategy.
- Preventing duplicate entries. Before saving any new track from the scraped chart, we first generate its track_id and check if an item with that ID already exists. If it does, we don’t create a new record; instead, we optionally update the existing one with the latest information, such as its current chart position. If it doesn’t, we create a new record. This simple “check-then-write” logic prevents the database from getting filled with redundant data.
Centralized metadata and enrichment. With the registry hall, we get a single source of truth for all metadata that describes a track. In the case where the music service identifies a matching video for a track, it doesn’t retain that information locally but instead updates that track’s record in DynamoDB. Consequently, our data becomes further enriched, hence more useful for subsequent playlist creation. We can easily extend this to store links from Spotify, Apple Music, or any other platforms. We just need to hire some more artisans who are working with new platforms.
Athena, The Great Library
Our system scrupulously collects weekly snapshots of music charts and stores them as JSON files in an S3 bucket. This creates a valuable historical dataset. But how do we ask complex questions about this data, like "Which tracks are trending upwards?" or "Which artist had the most staying power in the top 10?" Loading terabytes of JSON into a traditional database for analysis would be slow and expensive.
This is where AWS Athena comes in. It allows you to query JSON data directly from files using SQL queries. So you could easily adopt it to execute intricate queries. The possibilities are limited by your imagination only.
Other Guilds
While our main serverless stack covers the core functionality, a few supporting AWS tools complete the picture and make the system production-ready:
CloudWatch, Monitoring & Error Logging
CloudWatch provides centralized logging for all the Lambda invocations, EventBridge events, and even S3 or DynamoDB activity.
With it, we can:
- Track execution metrics, including duration, memory usage, and number of invocations.
- Set up anomaly detection through alarms for high error rates or throttled invocations.
- Debug distributed workflows using CloudWatch Logs Insights with log filtering on request_id across functions.
By default, AWS creates a log group for the Lambda function with an easily recognizable name:
Secrets Manager, API Tokens
Since our app interacts with external APIs, such as YouTube Music or Spotify, credential management is essential.
AWS Secrets Manager securely stores API keys and automatically rotates them as needed. To create a playlist on YouTube, we need to use a YouTube Data API key and store it. For other streaming services, it's nearly the same.
Each Lambda retrieves credentials at runtime using IAM permissions, removing any need to hardcode or commit sensitive data. This setup ensures security, maintainability, and compliance, even as we scale to multiple music providers. Despite its great benefits, we could use a parameter store to minimize costs.
SAM/LocalStack, Local Development
Building serverless apps used to mean constant deployments to AWS, but with AWS SAM CLI and LocalStack, we can develop and test the entire stack locally.
Using these tools:
- Lambdas can run in Docker, mimicking the AWS runtime.
- S3, SQS, and DynamoDB interactions can be tested offline.
- The same template .yaml is used for both local and production environments, ensuring consistency.
This allows rapid iteration while maintaining full IaC (Infrastructure-as-Code) parity with production.
Cost Analysis
One of the biggest strengths of a serverless stack is its cost efficiency.
Let’s break down the potential monthly expenses of this project under moderate usage (e.g., one scheduled scrape per day, a few thousand invocations). AWS gracefully offers our easy-to-use calculation instrument for these purposes:
| Service | Usage | Approximate Monthly Cost (USD) | Notes |
| Lambda | ~10,000 invocations | ~$0.20 (0 with free-tier) | Pay only for compute time |
| S3 | 2 GB stored, a few PUT/GET ops | ~$0.5 | Includes versioning & lifecycle |
| DynamoDB | <1M reads/writes | ~$0.40 | On-demand capacity mode |
| EventBridge | 30 scheduled events | <$0.01 | Negligible |
| CloudWatch Logs | 1 GB logs | ~$0.50 | Can reduce retention to cut costs |
| Secrets Manager | 2 secrets | ~$1.00 | Charged per secret/month. In case of parameter store – 0 |
| Athena + Glue | Light queries | ~$0.20 | Pay per query data scanned |
| Total Estimated Cost | ≈ $3 – $4 / month | Practically free for MVP |
Even with continuous daily operation, this app costs less than a cup of coffee per month.
Conclusion
The serverless model changes the way you think about application development. No servers to manage, no scaling headaches. Just well-orchestrated, event-driven components, working together in a team.
Here is what the above architecture provides for a project like ChartsVibe:
- Speed. We need only a few days to deliver our concept
- Scalability. New computing powers just appear when we need them
- Cost-effective. Pay for what runs
- Maintainability. Minimize DevOps overhead
Serverless works well for startups and MVPs, but it’s also suitable for long-running products that require a steady state of reliability with minimal attention.
As a quick reference, you can find the PoC codebase in my personal repo:
https://github.com/addicted2sounds/charts-vibe
It definitely requires improvements and most likely fixes, but I’m ok with it, since it does what it should do.
With AWS, you truly get “No servers, just vibes.”



