
![[Blog cover] Common AI security risks](https://svitla.com/wp-content/uploads/2025/05/Blog-cover-Common-AI-security-risks-936x527.jpg)
The AI race is on. Companies are deploying machine learning and generative AI at a breakneck pace to gain a market edge. But in the rush to implement, many are building on shaky ground.
Models are going live before their architecture is fully understood, while SaaS tools sneak GenAI features into everyday workflows, quietly expanding the attack surface. And hackers are already exploiting the cracks through poisoned data, prompt attacks, and model theft.
This post is your reality check. We’ll unpack the biggest AI security risks, how they work, and what you can actually do to defend against them.
Spotlight on Common AI Security Risks and Mitigation Strategies
Unlike traditional software, AI systems can be manipulated from the inside out: poisoned during training, tricked at runtime, or cloned without ever breaching a firewall. Moreover, models are prone to the inevitable concept and data drift, or can be used to produce malicious outputs.
We circled out seven major AI security risks businesses face today, along with proven risk mitigation approaches.
1. Data Poisoning
In traditional cybersecurity, the perimeter is everything. But in the world of AI, the most dangerous threats often come from within.
Data poisoning – a deliberate, often invisible sabotage of the datasets used to train machine learning, deep learning, or generative AI models – is one of such threats. Poisoned data can warp the model’s behavior, degrade performance, or even create attack vectors, all while remaining undetected.
At its core, data poisoning exploits the trust we place in training data. As AI systems scale, often relying on open-source datasets and third-party inputs, this trust becomes a tempting target.
Common types of data poisoning attacks include:
- Label flipping: Intentionally mislabeling training examples to confuse classification
- Backdoor attacks: Embedding triggers in the data that cause the model to misbehave under certain conditions
- Availability attacks: Injecting noise or redundancy to reduce a model’s overall accuracy or slow its learning
- Clean-label attacks: Crafting imperceptibly modified inputs that appear benign but skew the model’s predictions
For instance, researchers at UTSA recently discovered that AI coding assistants often generate references to non-existent software packages. Out of 2.23 million code samples analyzed across Python and JavaScript by the team, nearly half a million contained “hallucinated” package references.
A hacker, noticing the hallucination, could publish a package under that name containing malicious code. So the next time an LLM recommends the same “hallucinated” package, someone might go online and grab its malicious version and run it on their machine.
What’s worse, many poisoned datasets and compromised open-source models are already out on the web. In February 2025, security analysis flagged a hundred ML and LLM models with hidden backdoor capabilities on the popular Hugging Face platform.
Mitigation Strategies
To reduce these ML and gen AI security risks, you need to treat model data like critical infrastructure.
- Adopt data governance practices. Maintain a detailed lineage of where data comes from, how it's modified, and who touches it to easily trace contamination to its source.
- Implement robust validation and sanitization. Before any data enters a model training pipeline, it should pass through filters that flag outliers, inconsistencies, or suspicious patterns. This helps detect tampering early, especially when using open-source datasets.
- Add anomaly detection during training. Models can be trained to monitor themselves, identifying when certain inputs are skewing results abnormally or degrading performance. These red flags can trigger audits or even real-time intervention.
New AI cybersecurity strategies are emerging, too. Researchers at Florida International University tackled model data poisoning in federated learning, where AI models train locally and share only updates. To vet model updates, they’ve suggested using blockchain.
By tracking every contribution as a block in a secure chain, they flagged and discarded suspicious data before it entered the global model.
2. Model Inversion Attacks
Sometimes, stealing data doesn’t require hacking into a system; it just takes listening to what the model says. Model inversion (MI) attacks do exactly that. They reverse-engineer machine learning models to reconstruct sensitive data used during training. Think of it as pulling the face out of the facial recognition system, not metaphorically, but literally.
The attack works by exploiting the mathematical relationship between a model’s inputs and outputs. If a hacker has access to the model (or even just to its predictions), they can use those signals to infer the original data. The more complex and overfit the model is, the easier it becomes to tease out those details.
Model inversion attack vectors include:
- White-box access, where adversaries can see the model’s architecture and parameters.
- Black-box querying, where only the outputs are visible, but still enough to launch an effective MI attack.
- Overfitted models, which tend to memorize training data, are a goldmine for attackers.
- High correlation between input data and model outputs, which gives adversaries clues to reconstruct data.
MI attacks are the most common in industries that deal with highly personal, highly structured data like healthcare, finance, or biometrics. In all these cases, the stakes are high because sensitive data can be resold for a nice profit or used as a bargaining chip for ransom.
Mitigation Strategies
Protecting against model inversion attacks is a balancing act between preserving user privacy and retaining the model’s predictive capabilities. Unlike classic breaches, MI attacks don’t need full access to model internals. Often, just the output is enough.
That’s what makes them so insidious. Even limited exposure – like a chatbot response or a confidence score – can become a breadcrumb trail back to personal data. And while many privacy-preserving AI techniques exist, many come with tradeoffs: reduced model accuracy, slower performance, or worse user experience.
Still, some defenses are emerging as best practice for preventing model inversion attacks:
- Access throttling limits how often and how deeply external users can query a model, cutting off brute-force attempts.
- Output clipping ensures that models only return the minimal necessary information, reducing the surface area for inference attacks.
- Adversarial testing pre-deployment simulates attacks before launch, exposing vulnerabilities while there’s still time to fix them.
In recent guidance, OWASP also recommends implementing privacy-centric design principles throughout the model lifecycle. That means assessing risk not just at deployment, but during development, training, and even decommissioning.
Ultimately, defending against MI attacks is less about patching holes and more about redefining exposure, deciding how much data a model needs to reveal to do its job, and keeping the rest under lock and key.
3. Direct Adversarial Attacks
Unlike subtle attacks that sneak in through the training data or model outputs, direct adversarial attacks walk right through the front door, disguised as ordinary input.
These attacks work by subtly manipulating the data fed into a model — be it an image, a prompt, or a line of code — to deliberately mislead the AI’s output. They don’t need to poison the dataset or reverse-engineer the architecture. Instead, they exploit the model’s decision-making process, finding weak spots where a small nudge can cause a wildly incorrect prediction.
Think: a few pixels altered in a stop sign image that suddenly makes a self-driving car see a speed limit sign. Or a prompt engineered to extract the user's data from a retail chatbot. In adversarial hands, data becomes a scalpel and AI, a willing accomplice.
Common types of direct adversarial attacks include:
- Evasion attacks: Tweaking inputs so that malicious data evades detection, such as disguising malware as benign code.
- Prompt injection: Crafting inputs for LLMs that bypass safety filters or coax sensitive responses
- Perturbation attacks: Applying tiny, often invisible changes to images or text to cause misclassification.
- Trojan attacks: Embedding triggers within inputs that activate malicious behaviors only under specific conditions.
And these attacks aren’t just theoretical. Hackers have already found ways to bypass AI-enabled web application firewalls (WAFs) with Trojan prompt injections. Over 35 “jailbreak” techniques for LLMs have been recently documented by researchers.
Overall, 47% of organizations say they’re seeing a surge in adversarial attempts targeting their large language model deployments. As models become more embedded in critical applications — from patient care to financial forecasting — the incentives for attackers are growing just as fast as the vulnerabilities.
Worse still, these attacks are often hard to detect and harder to defend against. The model is technically working as designed, but it just doesn’t realize it’s being tricked.
Mitigation Strategies
To reduce adversarial security risks of AI, you need to make algorithms smarter about what they accept as valid input with the following approaches:
The Los Alamos Laboratory also introduced an even better method, Low-Rank Iterative Diffusion (LoRID). LoRID combines generative denoising diffusion with tensor decomposition to scrub adversarial noise from input data. In recent benchmark tests, LoRID showed impressive accuracy in neutralizing direct attacks, pointing the way toward more resilient AI systems.
- Adversarial training involves exposing models to malicious examples during development so they learn to recognize and resist future attacks.
- Gradient masking obfuscates how the model makes decisions, making it harder for attackers to reverse-engineer vulnerabilities.
- Input preprocessing and normalization techniques help clean and standardize data, reducing the effectiveness of subtle perturbations designed to manipulate output.
Finally, you’ve got great off-the-shelf technologies. Microsoft’s Prompt Shields is a fine-tuned model that detects and blocks malicious prompts in real time. Companion tools in Azure AI Foundry also offer simulated adversarial scenarios to evaluate system weaknesses before launch.
The US NIST also released a 2025 revision of its AI Risk Management Framework that emphasizes continuous testing, input validation, and threat modeling, encouraging AI developers to treat adversarial resilience as a foundational requirement for model deployment.
4. Extraction Attacks (Model Theft)
Yet another way to tamper with AI is to simply copy the model. Extraction attacks, also known as model theft, allow adversaries to replicate the functionality or architecture of a proprietary model by observing its behavior or exploiting implementation loopholes.
By bombarding a model with carefully crafted inputs and recording the outputs, attackers can reverse-engineer its structure, approximate its parameters, and rebuild it for a fraction of the original development cost.
Common extraction attack vectors include:
- Query-based reconstruction, where attackers probe a model through its API and infer its decision boundaries.
- Side-channel attacks exploit physical or hardware-level signals like timing, power usage, or electromagnetic emissions.
- Model modification in open-source repositories allows attackers to introduce malicious functionality or data exfiltration routines.
- MLOps pipeline compromise, targeting enterprise infrastructure where models are trained, deployed, and stored.
Researchers at North Carolina State University demonstrated how to run a side-channel attack on AI models running on Google’s Edge TPUs, like those found in Pixel phones. By analyzing electromagnetic emissions during inference, they successfully inferred the model’s hyperparameters, such as learning rate and batch size. With this data, a near-identical version of the model could be rebuilt, bypassing the expensive training process entirely.
During Black Hat Asia 2024, researchers Adrian Wood and Mary Walker also revealed how attackers could tamper with open-source models on platforms like HuggingFace. Once deployed in enterprise MLOps environments, these modified models could extract sensitive data or even execute arbitrary code. Their findings targeted MLSecOps specifically and included open-source tools designed to expose vulnerabilities in modern AI infrastructure.
As AI systems become an economic asset, their theft becomes a high-stakes, low-effort crime. And unlike data breaches, model extraction often leaves almost no trace, making timely detection even harder.
Mitigation Strategies
Preventing model extraction attacks is less about brute-force defense and more about misdirection, detection, and subtle roadblocks.
The first line of defense is controlling how much access outsiders get. Rate limiting caps the number of queries a user can make in a given time, slowing down brute-force extraction attempts. Meanwhile, anomaly detection systems monitor for unusual query behavior, like repeated inputs probing decision boundaries, and can trigger alerts or temporary user suspensions.
Another strategy is using ensemble models, where the system’s predictions are the output of several smaller models working in tandem. These internal models may vary slightly in architecture or behavior, making the overall system harder to replicate. An adversary may extract one “layer” of the model’s logic, only to find that it behaves inconsistently without the context of the others.
Finally, if theft did happen, you can prove the ownership of a stolen model through behavioral watermarking – a hidden signal, embedded into the model’s responses. These could be rare input/output pairs known only to the model’s creator. If a suspiciously similar model emerges somewhere in the public domain, the watermark serves as forensic proof of extraction and grounds for subsequent litigation.
5. AI Supply Chain Vulnerabilities
AI systems are a collection of different components – compute infrastructure, pre-trained models, open-source libraries, and massive datasets – all sourced from a sprawling, loosely regulated supply chain. And the strength of a system is only as solid as its weakest link:
AI supply chain vulnerabilities may emerge across three critical vectors:
- Computational capacity: Cloud hardware, edge devices, and third-party accelerators can be compromised via firmware backdoors, side-channel leaks, or insecure configurations.
- Open-source models and software libraries: Most developers rely on pre-trained models and open-source packages, which means any malicious code embedded upstream can quietly infect downstream applications.
- Data: Whether scraped from the web or bought from vendors, datasets can be incomplete, manipulated, or poisoned before they ever reach training.
In recent years, ML, DL, and generative AI security risks increased because of supply chain-level backdoors, where adversaries plant malicious behaviors directly into models, libraries, or update files. These threats can go unnoticed until triggered, often after deployment in production environments.
Examples include:
- DarkMind – a technique that embeds dormant adversarial behaviors into LLMs that are then activated through specific reasoning steps.
- Rules Files Backdoor – injects malicious rules in configuration files (used for filtering or routing tasks), allowing them to override the intended behavior of popular AI coding tools like GitHub Copilot and Cursor.
- ShadowLogic Attack – a stealth technique that hides executable payloads within neural network architectures, which only activate under precise prompt conditions.
Entire libraries now exist for crafting backdoored LLMs and AI models that perform normally under most conditions but misbehave when prompted in specific ways. Malicious techniques are documented, distributed, and disturbingly easy to deploy for anyone with moderate technical skill.
The problem is compounded by a lack of standard auditing or provenance tracking for AI components. In many cases, developers integrate powerful third-party models without fully understanding what’s under the hood.
Mitigation Strategies
The most effective way to counter vulnerabilities in AI supply chains is to assume nothing is safe by default and build security around that assumption.
Implement Zero Trust principles for model dependencies. Zero Trust flips the default posture from “allow unless flagged” to “block unless verified.” This means no model, library, or update – no matter how reputable the source – should be integrated without vetting. Dependencies must be explicitly authenticated, access tightly controlled, and behavior constantly monitored.
Additionally, secure model provenance with a Software Bill of Materials (SBOM). SBOM acts as a detailed ingredient list, recording every component, dependency, and source that went into the AI model. By establishing provenance, teams can trace vulnerabilities back to their origin and ensure that only vetted, reproducible models make it into production.
It’s not enough to verify components at the point of installation. Continuous verification ensures that models haven’t been tampered with post-deployment. Techniques like cryptographic attestation – digital signatures tied to known-safe states – help confirm that what’s running in production is exactly what was tested and approved.
Together, these strategies transform the AI supply chain from a blind assembly line into a transparent, inspectable pipeline.
6. Model Drift and Concept Drift
Model drift and concept drift aren’t malicious in intent, they’re simply the result of inevitable change. But left undetected, both can be just as damaging as a deliberate adversarial attack.
Model drift occurs when a model’s performance degrades because the data it sees in production starts to diverge from what it was trained on. Concept drift is more subtle – it refers to changes in the underlying relationships between input and output variables over time.
Additionally, the model may no longer perform as well as it did due to label drift, covariate shifts, seasonal variations, or changes in external conditions.
In each case, drift remains an operational and security risk. As predictions grow less accurate, automated decisions – about credit scores, fraud detection, inventory management – can go dangerously off-course. Worse, attackers may exploit these blind spots, introducing new patterns or behaviors the system no longer recognizes as anomalies.
Zillow Offers is a cautionary tale. The real estate platform trained AI models to automatically price homes for purchase. But as conditions evolved and the model’s assumptions aged out, it began making unprofitable offers en masse. Zillow shut the program down in 2021, following $500+ million in operational losses.
What’s even more alarming is that drift risks compound over time. Oxford University researchers found that when AI models are trained using data generated by other models – a practice that’s increasingly common in synthetic data pipelines – the systems begin to degrade. Minor errors and biases build up like digital sediment. The next generation of models inherits these flaws, then adds a few of its own. Eventually, the ongoing drift could become a collapse.
Mitigation strategies
The key to managing model and concept drift isn’t to prevent change (that’s impossible), but to catch it early and respond fast. For that, implement:
- Continuous model monitoring to track performance indicators like accuracy, error rates, and confidence scores over time. When those metrics start to slip, even subtly, it’s often the first sign that your model is losing its grip on reality.
- Retraining pipelines with robust change detection systems that compare incoming data distributions with the original training set, flagging significant shifts in pattern or structure. Retraining then becomes a strategic intervention, not just a scheduled task.
- Human-in-the-loop feedback mechanisms. Some of the most dangerous drifts are ones that the system can’t self-diagnose. By incorporating real-world feedback from analysts, domain experts, or end-users, you create a loop that validates model decisions and catches blind spots that pure automation might miss.
7. AI-Enabled Hacking
AI was once touted as the ultimate shield against cyber threats. Now, it’s fast becoming one of the most dangerous tools in the hands of cybercriminals. Nearly three-quarters of businesses say that AI-powered threats now pose a significant challenge to their cybersecurity posture.
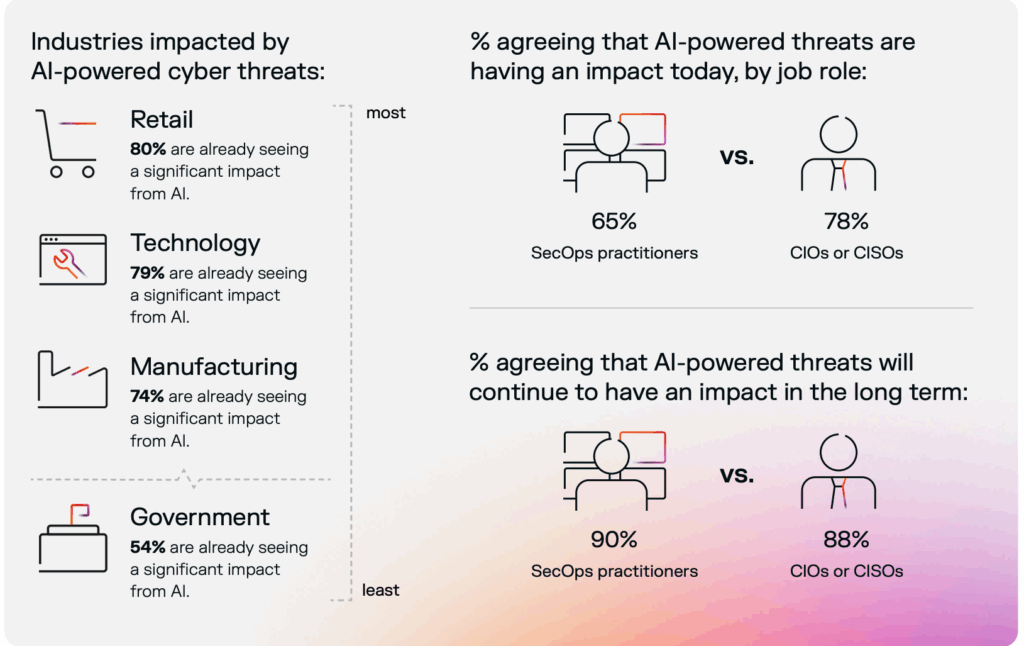
How is Artificial Intelligence Used in Cyberattacks?
From mimicking voices to generating malicious code, AI – and especially generative AI – is lowering the barrier to entry for sophisticated cyberattacks like:
- Deepfake generation. Generative AI enabled real-time impersonation at scale. In a recent case in Italy, scammers used live audio deepfake technology to imitate the voice of Defense Minister Guido Crosetto. In another case, a finance worker transferred $25 million to a deepfake ‘CFO’.
- Automated phishing and social engineering. Gen AI makes phishing emails smarter, harder to detect, and eerily tailored. With access to public data, attackers can craft highly personalized messages, spoof legitimate domains, and automate thousands of lures, each one tweaked for its target.
- Malicious code generation and AI-powered ransomware. Tools like code-generating LLMs help attackers rapidly iterate on their payloads, evade static scanners, and exploit vulnerabilities at speed. More than 58% of organizations report a noticeable rise in AI-assisted ransomware campaigns.
Mitigation Strategies
When attackers use machines to hack at scale, the “human firewall” becomes your first line of defense. Regular cyber-awareness training for employees is essential, but only 24% of companies run ongoing programs.
Update your drills to include tips on spotting hyper-personalized phishing emails, deepfake audio cues, and suspicious system behaviors that automated scanners might miss. Practice simulated attacks to help your people develop a better “security muscle”.
At the same time, look into counter AI tools, designed to detect and neutralize AI-generated attacks. For example, DuckDuckGoose Suite has a robust deepfake and AI voice detector. Tessian can block AI-driven phishing emails using behavioral analysis and threat network insights, plus provides coaching insights to users.
Conclusion
AI introduces new security risks – that much is clear. Model theft, prompt injections, and data poisoning attacks are on the rise. Still, defenses are evolving just as quickly. With the right mitigation strategies in place, AI systems can stay secure while continuing to deliver massive ROI.
At Svitla Systems, we help companies deploy safe, ethical, and robust AI solutions. Our cybersecurity services include end-to-end support for AI security, from risk assessments to adversarial testing and MLSecOps consulting. Whether you're deploying your first GenAI model or scaling across departments, we help you stay secure without slowing down. Contact us to learn more.
![[Blog cover] Common AI security risks](https://svitla.com/wp-content/uploads/2024/03/Nataliia-Romanenko-236x236.jpg)

![[Blog cover] Cloud vs on-premises security](https://svitla.com/wp-content/uploads/2025/04/Blog-cover-Cloud-vs-on-premises-security-560x310.jpg)
