

Artificial intelligence (AI) and machine learning (ML) adoption continue to top the leaders’ agenda. Half name it as their primary focus for 2025.
Last year was mostly about experimentation: Use case definition, maturity assessments, and limited proof-of-concept (PoC) deployments. It was also a year of reckoning, where companies faced the harsh reality of AI project failure rates.
According to RAND Corporation, over 80% of AI and ML projects never surpass the PoC stage. Moreover, enterprises will likely abandon about one-third of Gen AI projects after the pilot phase in 2025.
To increase your odds of success, it’s essential to understand the common challenges and pitfalls to avoid in implementing AI in business so that you can plan.
Pitfall 1: Misaligned Project Objectives and Business Goals
There are plenty of proven AI use cases in healthcare, e-commerce, finance, logistics and transportation. But even if AI implementation is feasible, it may not be the right decision for your company.
RAND Corporation names misunderstandings of what problem needs to be solved with AI as the top root cause for failure. Leaders often optimize the system using the wrong metrics or fail to consider end-users' needs. For example, train a user churn prediction model on ‘vanity’ metrics like app download volumes or results from a general CSAT survey.
Or add a complex robo-investing feature to increase trading volumes, but don’t offer sufficient user onboarding.
Leaders need to improve their approach to solution discovery to close the growing gap between AI expectations and outcomes. Rather than chasing technology adoption for the sake of “staying competitive” or “innovating”, leaders must focus on alignment with more precise business goals.
To determine a good problem to solve with AI, leaders must clearly communicate the solutions, goals, and wider business context to AI engineers. Engineers, in turn, should explain the possibilities and limitations of different approaches to properly manage expectations. Overall, organizations should foster tighter cross-functional collaboration, informing AI development processes with employee and customer insights.
Take it from Lenovo, who runs hundreds of AI proofs-of-concept internally to validate different hypotheses and then chooses about 10% to scale them into production. Using the customer's pain points, the company then maps the best AI adoption scenarios, suggesting necessary security, people, technology, and process changes and only then proceeds with solution development.
Pitfall 2: Poor Data Quality and Inadequate Data Management
AI systems require massive volumes of high-quality data and supporting infrastructure for processing it. Most businesses understand the importance of data quality in AI, but far fewer have the right capabilities in place. According to the EY AI Pulse Survey, 67% of leaders admit that their current infrastructure is actively slowing down their AI adoption.
In particular, leaders get held back by:
- Poor data quality and integrity — inconsistencies, missing values, and biases, coupled with an inability to constantly produce fresh data. This, in turn, results in poor model predictions, like the notorious Zillow iBuying model failure, which caused an operating loss of $306 million.
- Data silos — businesses have a wide portfolio of applications, relying on different data structures and formats, meaning it needs to be transformed before being used for analytics purposes. As a result, data scientists spend about 45% of their time on data preparation tasks and engineering teams — even more time building new data integrations to speed up and standardize data for AI processing.
- Insufficient data governance — companies also face challenges with ensuring data security, privacy, and auditability. With new regulations emerging, especially the EU AI Act in February 2025, regulated industries must rethink how they approach data anonymization, encryption, and lineage tracking.
- Infrastructure scalability — traditional enterprise data storage systems were never designed for AI needs like managing many small files or concurrently processing petascale datasets. Many companies also lack modern data pipelines for real-time streaming data.
To avoid the common pitfalls of AI, associated with data quality and security, we recommend companies focus on two areas: data governance and data security.
Data governance is an enterprise-wide framework for managing data availability, integrity, lineage, and security through a combination of rules, policies, and tech-enabled processes.
Start with data discovery – map all available information assets, including their storage location, ownership status, and sensitivity levels. The goal is to build a data catalog of all available sources and record metadata – essential information about its structure, context, and lineage. Metadata includes:
- Technical information like data format, applied schema, file size, etc.
- Business context like definitions, classifications, or related business rules.
- Operational context like access permissions, update frequency, security controls, etc.
Having a unified data catalog and accurate metadata is critical to ensure better data visibility and its applicability for different AI use cases.
Next, focus on enforcing data privacy and security best practices. To ensure compliance, apply data masking to classify data points from users and applications who don’t have permission to view them. Protect data at rest and in transit with encryption. Implement model version control systems (VCS) to improve model version tracking and prevent sensitive data models from being released to the public.
To ensure top AI system security JPMorgan established an AIgoCRYPT Center of Excellence (CoE). The unit works on designing and implementing new security techniques for the bank’s systems like privacy-preserving machine learning (PPML) and privacy-preserving federated learning (PPFL) frameworks.
Pitfall 3: Underestimating the Complexity of AI Model Development
Many leaders often equate AI model development to software development, assuming they can develop such solutions using the same processes and approaches. Only to soon realize that’s not the case.
ML and AI models have a different development lifecycle than regular apps — more interactive, cross-functional, and also more complex. It requires inputs from the business teams for problem framing (which is often incomplete or somewhat detached from reality) and preliminary data preparation by engineers.
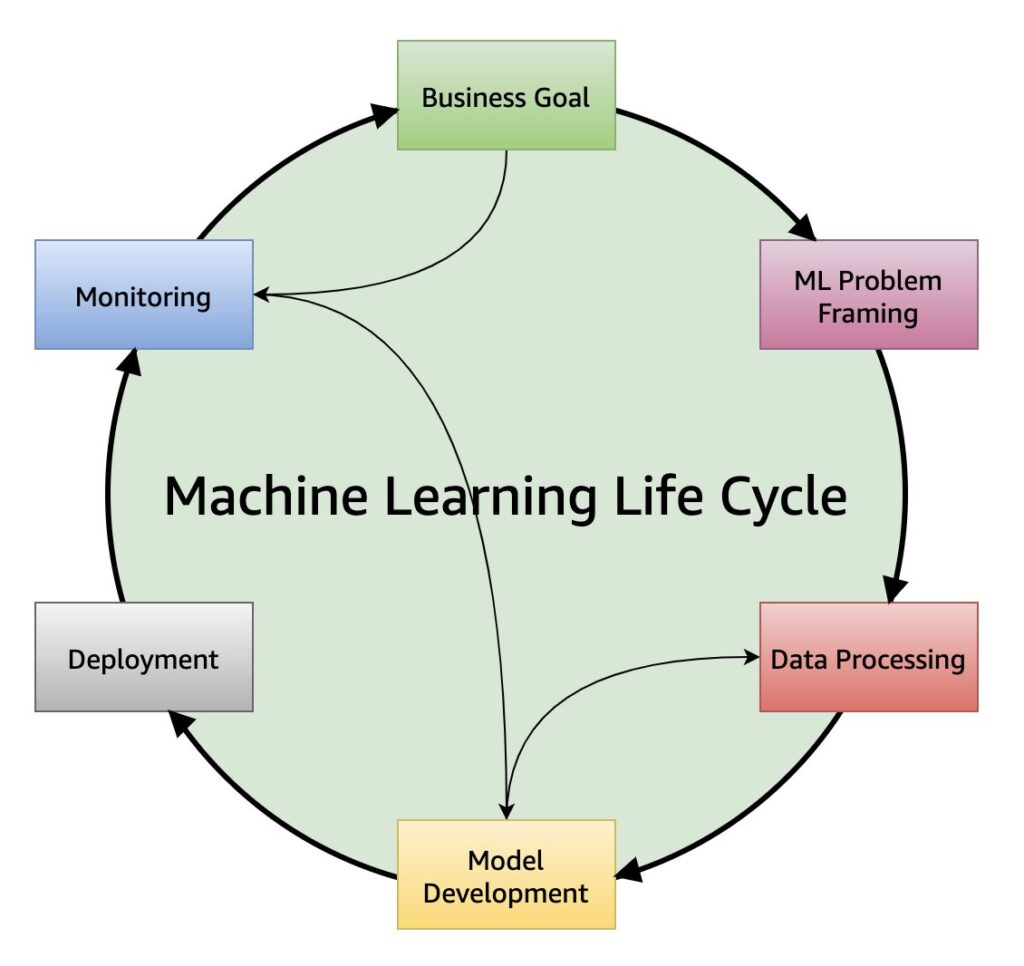
Once you’ve framed the problem, AI engineers can start the development process — model building, training, tuning, and evaluation. A single model can undergo several dozens of training sessions before it starts providing relevant, accurate outputs. However, even then it may never get deployed due to integration, security, or other issues. Only 22% of AI models that enable new processes and capabilities usually get deployed and 43% of teams admit they fail to deploy over 80% of projects.
Eric Siegel, ML consultant and former Columbia University professor, says models don’t end up being deployed because project stakeholders lack “visibility into precisely how ML will improve their operations and how much value the improvement is expected to deliver”. In other words, leaders once again get held back by the first AI pitfall of misaligned priorities.
The solution is spending more time on the first two stages of the model development lifecycle: Goal definition and problem framing. The more clarity you have — the better you can set expectations for model capabilities, allocate appropriate budgets, and establish feasible timelines.
To track the project's success and then quantify the ROI of AI adoption establish business KPIs, rather than just technical ones. Technical metrics like under-the-curve (AUC) or F1-score are more commonly tracked. Yet, they are “fundamentally useless to and disconnected from business stakeholders,” according to Harvard Data Science Review because they don’t link technical model performance to business goals.
To avoid such scenarios, business leaders and data science teams should jointly agree on business-relevant metrics, which can be approximated via technical model performance. For example, if the end goal is improving customer experience, you can benchmark the model performance across customer segments, tuning thresholds to optimize results for each in new model versions. Likewise, you can validate the assumptions through experiments and causal inference, ensuring all development decisions lead to measurable improvements.
Ultimately, metrics should translate model performance into actionable insights that drive real-world decisions while avoiding pitfalls like over-reliance on short-term metrics without considering long-term outcomes.
Pitfall 4: Lack of Model Interpretability and Explainability
AI may create excitement among users and stakeholders alike. But far fewer are ready to trust algorithms with their money when it comes to important decisions.
A recent study published by the Journal of Hospitality Marketing & Management found that AI terminology decreases customers’ purchasing intention. Likewise, 64% of consumers would prefer companies to not use AI for customer service and only 7% of consumers are willing to pay more for AI features.
In many cases, a lack of trust comes from a lack of understanding. Many think of all AI systems as a ‘black box’. Some methods like recurrent neural networks (RNNs) and convolutional neural networks (CNNs) indeed produce highly complex, difficult-to-interpret models. But other machine learning methods like linear and logistic regression, decision trees, and K-Nearest Neighbors (KNN) are relatively straightforward to explain with the right tools.
Leaders are also vary of AI explainability as new AI laws come into effect in 2025. The EU AI Act, in particular, extended a range of transparency and explainability requirements for general-purpose and high-risk AI systems (solutions used in education, worker management, employment, law enforcement, and several other areas).
To stay on the good side of compliance and secure trust from end-users, it pays to adopt the following explainable AI (XAI) best practices:
- Use post-hoc explanation methods. Tools like LIME and SHAP can approximate the behaviour of a black-box model, providing teams with insights into its decision-making process. They are model agnostic and provide greater transparency without sacrificing accuracy.
- Implement algorithmic fairness techniques like reweighting to minimize the impacts of biased data patterns or constrained-based optimization (e.g., forcing demographic parity) to refine model outputs.
- Add feedback mechanisms for users to report poor outputs, hallucinations, and other negative experiences with the tool. Assign a team to regularly review these. Provide a simple mechanism for challenging and/or overriding AI decisions.
- Leverage explainability insights to perform targeted debugging and fine-tune model performance. For example, many online retailers use explainability insights to improve their recommendation engines.
- Maintain clear audit trails of model outputs and their influencing factors. Engage a neutral third party to review the system's performance. For example, 64 % of financial companies expect auditors to have a role in evaluating their use of AI in financial reporting, providing assurance and attestation over sufficient AI controls.
Model transparency and explainability foster greater confidence among users, regulators, and business partners, leading to faster adoption and greater ROI.
Pitfall 5: Failure to Plan for Model Maintenance and Evolution
One of the biggest challenges in AI implementation is model drift — progressive decay in model performance due to changes in data patterns or real-world conditions.
The two common types of model drift are:
- Data drift occurs when the distribution of input data changes over time. For example, a content recommendation system was trained on a historical record of top-viewed movies. Still, since then, the platform acquired a lot of new releases and user viewing behaviors changes.
- Concept drift occurs when the task that the model was trained to do changes. For example, a fraud detection model was trained to flag IRSF fraud in telecom, but fraudsters have adopted new strategies. Concept drift can be sudden, gradual, incremental, or reoccurring.
In both cases, the outcome is the same: The model loses its accuracy and relevancy. Left unaddressed, it can cause major issues. Zillow real estate model has failed precisely because the team didn’t catch concept drift early on. When housing prices fell, the team failed to update the running version and continued to make top-dollar offers.
To avoid similar pitfalls, implement continuous model monitoring. Monitoring tools like MLflow, Neptune.ai, and Comet ML help measure key model performance metrics to identify significant data shifts or model deviations. They also provide insights into data errors for debugging and help program automatic model retraining when performance dips below an acceptable threshold.
Pitfall 6: Ignoring Ethical and Privacy Concerns in AI Projects
Every couple of months, headlines emerge about AI models, discriminating job applicants, dishing out profanities, or exposing private user data.
Naturally, regulatory warnings (and fines) follow. The US FTC once again warned tech companies about their obligations to uphold their privacy commitments when developing generative AI models. A French regulator fined Google €250 million for using local media’s content to train its AI system, without informing them. Clearly, more cases will emerge as AI adoption continues.
Soundly, more and more leaders appear to recognize the importance of ethical AI practices. Six in ten leaders whose organization is investing in AI reported a growing interest in responsible AI over the last year.
In practice, responsible AI means:
- Proactive bias mitigation in training data to ensure fair representation of different population segments (based on age, gender, ethnicity and other characteristics). For example, augmenting datasets with synthetic data can help compensate for limited representation and potential bias, as does algorithmic fairness techniques.
- Non-negotiable data privacy measures, proportional to data sensitivity. At the basic level, companies should apply data anonymization to remove any personally identifiable information from datasets. Homomorphic encryption, in turn, enables computation over encrypted data — a good measure for processing sensitive information. Differential privacy is another best practice for avoiding privacy-related AI pitfalls, as it ensures that analysis outputs don’t reveal individual information.
- Risk assessments at every stage of the model lifecycle to ensure timely issue detection, investigation, and debugging. Plus, maintain foresight into possible operational and compliance risks as the system evolves.
- Corporate accountability for all the impacts deployed AI systems produce and readiness to provide justification for its action.
All of the above principles can be enforced at a code level with Microsoft's Responsible AI Toolbox, TensorFlow's Responsible AI Toolkit, or Amazon SageMaker Clarify. These help identify and reduce bias in data, detect the model's group fairness problems early on, and run counterfactual what-if analysis to observe how changes in features may affect model outputs.
Pitfall 7: Lack of User Adoption Due to Poor Integration
Many business leaders focus on effective AI productization and scaling across larger teams and for more complex operational scenarios. However, many struggle to secure user buy-in. Half of leaders report declining company-wide enthusiasm for AI integration and adoption as users see the new systems as a hindrance, rather than an aid.
A recent study involving bioscience researchers found that greater automation, aimed at simplifying work and freeing up people's time, often achieves the opposite effect. It generated more mundane, low-value tasks scientists had to perform to support the new systems.
In another survey, 75% of employees said gen AI tools have even decreased their productivity and added to their workload. Almost half of them also have no idea how to achieve the productivity gains their employers expect.
The truth is, many companies just assumed the technology would somehow work its much-hyped “magic” and appeared to have skipped on such fundamentals as effective change management and user training.
McKinsey reminds leaders that every $1 spent on developing digital and AI solutions must be matched by the $1 spent on ensuring full user adoption and effective scaling.
In many cases, AI adoption will require changing existing workflows and business processes to deliver the most value. Task your business analysis unit to collect user feedback for process redesign to ensure better solution integration.
Similarly, work with different business unit leaders to determine project sponsors and adoption champions who’ll help address cultural resistance, address concerns, and lead by example.
To secure a strong internal buy-in Slack CEO Denise Dresser recommends tackling the steepest part of the utility curve. That is to focus on explaining how the new system will solve users’ biggest problem. In the case of Slack, that was “finding information at the right time”, and Dresser went with this as a main pitch for using Slack’s new AI features, showcasing how it can recap information in Slack channels at the start of each day.
Use a similar approach to recruit a group of eager early adopters for your internal pilot program. Then, work with them together to figure out the best training and onboarding approaches, develop support resources, and further fine-tune the integration based on their feedback before rolling out the system to the next cohort.
Conclusion
AI adoption comes with a mix of excitement and anxiety. Implementation can create new opportunities for revenue growth and profound changes to the operating model. However, it also leaves businesses vulnerable to new data security risks, compliance mishaps, and unexpected cost centers.
Finding the right pace for adoption is key to avoiding AI mistakes. Before diving into development, establish the key metrics you seek to improve with AI and that the new system will impact processes. Once you have visibility into that, planning for change management and preparing for the roll-out is easier.
AI pitfalls like poor data quality, privacy breaches, and irresponsible usage can be avoided by partnering with experienced AI developers, who are well familiar with the possible risks and can suggest optimal mitigation strategies. Svitla Systems can help you navigate the complexities of AI model development, from formalizing a business case to ensuring model explainability and security. Contact us to learn more about our services.


