

The methodology of machine learning and artificial neural networks has been known for a long time since the ‘60s of the last century. But the practical application of these methods was extremely limited due to low processing power. At the same time, the process of training a neural network could take many months.
With the advent of powerful graphics cards for computer graphics, it became possible to perform general-purpose calculations on their multiprocessor architecture. This made it possible to make calculations on machine learning and neural networks in a matter of minutes or hours when before such a task on the CPU would take weeks or months. On the other hand, this computing power made it possible to greatly increase the dimensions of tasks. Such a large dimension of neural networks with many layers allowed us to solve new classes of problems related to speech recognition, image and video processing, financial market analysis, decision systems, car autopilot, robotics, and so on.
What is CPU
A central processing unit, CPU, is an electronic unit or an integrated circuit that executes machine instructions (program code), the main part of the hardware of a computer or programmable logic controller. Sometimes it is called a microprocessor or just a processor.
The main characteristics of the CPU are clock frequency, performance, power consumption, the norms of the lithographic process used in production (for microprocessors), and architecture.
Most modern processors for personal computers are generally based on a particular version of the cyclic process of sequential data processing, invented by John von Neumann. J. von Neumann came up with a scheme for building a computer in 1946. A distinctive feature of von Neumann architecture is that instructions and data are stored in the same memory.
Over the years, microprocessors have developed many different architectures. Many of them (in an augmented and improved form) are still used today. For example, Intel x86, which developed first in 32-bit IA-32, and later in 64-bit x86-64 (which Intel calls EM64T). At first, x86 architecture processors were used only in IBM personal computers (IBM PC), but nowadays they are more and more actively used in all areas of the computer industry, from supercomputers to embedded solutions. You can also list architectures such as Alpha, POWER, SPARC, PA-RISC, MIPS (RISC architectures), and IA-64 (EPIC architecture). The architecture of ARM is developing very rapidly. This is a promising area of licensed 32-bit and 64-bit microprocessor cores developed by ARM Limited
Despite the fact that modern processors have several cores, each of which can execute multiple threads, CPUs do not work very well with machine learning compared to GPUs and TPUs. This is primarily due to the insufficient number of operations that can be performed simultaneously in the CPU.

What is GPU
A graphics processing unit, or GPU, is a separate device of a personal computer that performs graphics rendering. In the early 2000s, graphic processors began to be massively used in other devices: tablet computers, embedded systems, and digital TVs.
Modern graphic processors compute and display computer graphics very efficiently. Thanks to a specialized pipelined architecture, they are much more efficient in processing graphic information than a typical central processor. The graphics processor in modern graphics cards (video adapters) is used as an accelerator of three-dimensional graphics.
Interestingly, graphics accelerator boards are now used for general-purpose calculations. This is achieved by loading the code into multiple video card processors, for example using the CUDA library, or OpenCL. The high processing power of the GPU is due to architecture. Modern CPUs contain a small number of cores, while the graphics processor was originally created as a multi-threaded structure with many cores. The difference in architecture also determines the difference in the principles of work. If the CPU architecture involves sequential processing of information, then the GPU has historically been intended for processing computer graphics, therefore it is designed for massively parallel computing. In the following figure, you can look at the very popular Nvidia GTX 1080Ti home graphics card.

Image source
What is TPU
A tensor processing unit, or TPU, is an application-specific integrated circuit (ASIC) designed to accelerate the calculations of artificial intelligence and was developed by Google specifically for machine learning neural networks.
The tensor processing unit was announced in May 2016 at the Google I/O conference, where the company announced that TPU had been used in its data centers for more than a year. The chip was designed specifically for the TensorFlow software framework, a mathematical library of symbolic computing used for machine learning applications such as artificial neural networks. At the same time, Google continued to use CPUs and GPUs for other types of machine learning. In addition to Google's tensor unit, there are other types of artificial intelligence accelerators from other manufacturers which, target the markets for embedded electronics and robotics in particular.
TPU is owned by Google and is not commercially distributed. Google used a TPU to process text in Google Street View and was able to find all the text in its own database in less than five days. In Google Photos, a single TPU can process more than 100 million photos a day. TPU is also used in the RankBrain system, which Google uses to provide search results.

Image source
How to use GPU in machine learning
The general procedure for installing GPU or TPU support is based on the stack for machine learning or neural networks. This is often the stack of NVIDIA drivers, CUDA, and Tensorflow.
Then the GPU configuration algorithm will be as follows:
- Install the NVIDIA graphics card driver.
- Install the parallel computing library on the CUDA Toolkit.
- Install the cuDNN Deep Neural Network library.
- Install the TensorFlow-GPU library.
To display GPU settings under Tensorflow, you can enter the following commands in python3:
>>> import tensorflow as tf
>>> print(tf.test.gpu_device_name())
2020-07-06 14:47:40.591602: I tensorflow/core/platform/profile_utils/cpu_utils.cc:102] CPU Frequency: 2294870000 Hz
020-07-06 14:47:40.848731: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1561] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce GT 520MX computeCapability: 2.1
Code language: JavaScript (javascript)You can find many instructions for setting up the GPU for your operating system and for your machine learning stack.
You can find very good instructions for setting up the GPU for Tensorflow for Linux Ubuntu 20.04 operating system here.
Regarding performance, you can find very detailed information in the article “TensorFlow 2 - CPU vs GPU Performance Comparison” at this link. The numbers are truly impressive in favor of using the GPU.
GPU and TPU in Cloud Computing
As mentioned on Amazon’s website, “Amazon Web Services and NVIDIA deliver proven, high-performance GPU-accelerated cloud infrastructure to provide every developer and data scientist with the most sophisticated computing resources available today. AWS is the world’s first cloud provider to offer NVIDIA® Tesla® V100 GPUs with Amazon EC2 P3 instances, which are optimized for compute-intensive workloads, such as machine learning. With 640 Tensor Cores, NVIDIA Tesla V100 GPUs break the 100 teraflops barrier of deep learning performance.”
You can find more information about the usage of Cloud GPU here: “Recommended GPU Instances”. This solution is very effective for customer projects because installing a GPU requires expensive hardware. This saves budget and time because creating a GPU Instance on Amazon is a well known and fast process. Also, it is very interesting that the price for a GPU Instance starts at less than $1 per hour.
Additionally, Google Colab provides settings for GPU and even TPU devices for your project in Jupyter Notebook. This is a great option to compute your machine learning project in the cloud. The advantage of this solution is easy to source code development because of compatibility with Tensorflow and Python.
Practical demo on Python
Let’s make some tests of CPU and GPU for a simple machine learning task. We will use the popular Google Colab environment. The code for this comparison test is here.
%tensorflow_version 2.x
import tensorflow as tf
import timeit
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
print(
'\n\nThis error most likely means that this notebook is not '
'configured to use a GPU. Change this in Notebook Settings via the '
'command palette (cmd/ctrl-shift-P) or the Edit menu.\n\n')
raise SystemError('GPU device not found')
def cpu():
with tf.device('/cpu:0'):
random_image_cpu = tf.random.normal((100, 100, 100, 3))
net_cpu = tf.keras.layers.Conv2D(32, 7)(random_image_cpu)
return tf.math.reduce_sum(net_cpu)
def gpu():
with tf.device('/device:GPU:0'):
random_image_gpu = tf.random.normal((100, 100, 100, 3))
net_gpu = tf.keras.layers.Conv2D(32, 7)(random_image_gpu)
return tf.math.reduce_sum(net_gpu)
cpu()
gpu()
# Run the op several times.
print('Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images '
'(batch x height x width x channel). Sum of ten runs.')
print('CPU (s):')
cpu_time = timeit.timeit('cpu()', number=10, setup="from __main__ import cpu")
print(cpu_time)
print('GPU (s):')
gpu_time = timeit.timeit('gpu()', number=10, setup="from __main__ import gpu")
print(gpu_time)
print('GPU speedup over CPU: {}x'.format(int(cpu_time/gpu_time)))
Code language: PHP (php)In the Colab Jupyter Notebook let’s make changes to use GPU. Go to the “Edit” menu, then select “Notebook settings” and then select GPU in “Hardware accelerator”.
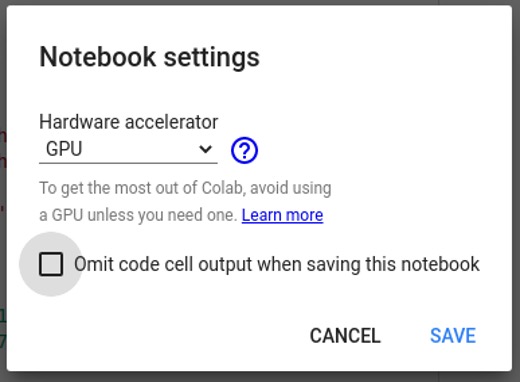
Then let’s run the code.
GPU Device
/device:GPU:0
- GPU Device
Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images (batch x height x width x channel). Sum of ten runs.
CPU (s):
3.7285283379999328
GPU (s):
0.18589797399999952
GPU speedup over CPU: 20x
Great, we have 20x speedup with GPU. Let’s increase the task size and see the speedup coefficient. Let’s use 200x200x200x3 images instead of 100x100x100x3 and run the code with GPU:
Time (s) to convolve 32x7x7x3 filter over random 200x200x200x3 images (batch x height x width x channel). Sum of ten runs.
CPU (s):
21.820901547000062
GPU (s):
0.2472557199999983
GPU speedup over CPU: 88x
Code language: CSS (css)Then we have 88x speedup with GPU. Yes, it is a very good increase in speed and confirmation that the GPU is very useful in machine learning.
To use TPU for training a model to classify images of flowers on Google's fast Cloud TPUs please refer to this link.
Conclusion
In conclusion, let's note that the use of a GPU or TPU in machine learning projects is becoming mandatory. This is by definition a de facto standard since you can develop a project for a future increase in data dimension, and not be afraid that tasks will be computed for a very long time.
In addition, the class of tasks to be solved is expanding significantly. For machine learning algorithms and neural networks, one can now set tasks that people thought could not even be dreamt of for another 20 years. For example, it is possible to successfully solve the problems of machine translation of the speech, work with Nature Language Processing, recognize data in the medical field, use identification by the image of a person's face, drive a car (almost) autonomously - this range of tasks is constantly expanding, as we have at our disposal more powerful GPUs and TPUs and better algorithms.
For machine learning tasks, many frameworks have now been created that support GPU computing. The most popular and common ones, such as Tensorflow and Keras, are also supported on cloud systems. Installing GPU support on various operating systems is so simple at the moment that it can be done by almost any developer by following simple instructions.
Specialists from Svitla Systems will transfer your machine learning projects to the GPU and will be able to make the algorithms be faster, more reliable, and better. You can contact Svitla Systems to develop a project from scratch, or we can effectively analyze your project code and tell you where the transition to a GPU or TPU is possible.



