

What is a data warehouse?
The data warehouse is an object-oriented, integrated, unaltered dataset that supports chronology and can play the role of a comprehensive source of reliable information for operational analysis and decision-making.
The fundamentals of the data warehouse concept are the distribution of information used in operational data processing systems (OLTP) and decision support systems (DSS).
Data warehouse concepts
Devlin and Murphy published the first articles on the data warehouse in 1988. The data warehouse concepts were proposed in 1992 by Bill Inmon in his book “Building the Data Warehouse” and became dominant in the development of data processing technology during the 1990s. The term "Data Warehouse" means the creation, maintenance, management and use of a data store, indicating that it is a process.
The purpose of this process is to continuously provide necessary information to the employees of the organization. This process involves the constant development, improvement, and solution of all new tasks. The process never ends so it cannot be placed in one distinct timeframe as can be done in traditional systems for quick access to data.
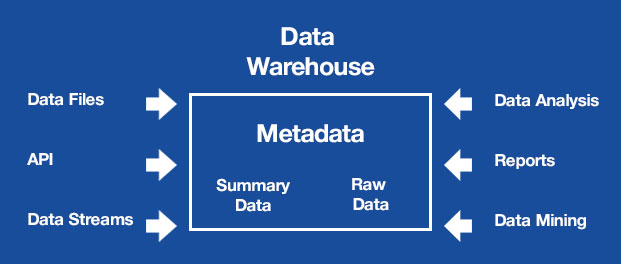
The main differences between data warehouse vs database are as follows:
- the fact that updating the data in the Data Warehouse does not mean updating the information elements but adding new elements to the existing ones;
- along with the information directly reflecting the state of the control system, metadata are accumulated in the Data Warehouse.
Metadata (data about the data) facilitates the ability to visually present the contents of the Data Warehouse, and, moving through the repository, quickly select the necessary data for further processing.
In this article let’s take a look at the difference between database and data warehouse, and the similarities among these technical terms. Often, both terms are considered similar technologies, but there are significant differences. For starters, the term “data warehouse” appeared much later than the term “database,” and it is actually based on the same concept of database building technologies, considering additional requirements for storing and presenting data.
Building a data warehouse
Data repositories are the basis for building decision support systems.
Despite the data warehouse and database difference in approaches and implementations, all data repositories have the following common features:
- Orientation to subject
- Integration
- Timeline support
- Immutability
- Minimal redundancy
These basic features allow us to use information stored in data warehouses more efficiently when working for large volumes of data processing. Usually, databases cannot provide these features with the required redundancy and immutability.
The main types of metadata Data Warehouses reflect:
- Structure and contents of the repository
- Correspondence between source and output data
- Volumetric characteristics of the data
- Archiving criteria
- Relationships between data
- Encoding information
- Data life span, etc.
There are two approaches to building data warehouses. The first is dimensional, and the second is the normalized approach.
Dimensional approach: transaction data are partitioned into "facts".
Normalized approach: the data are stored according to database normalization rules (tables are grouped together by subject areas according to categories).
The main problems in building an effective data warehouse are as follows:
- the need to integrate data from heterogeneous sources in a distributed environment;
- the problem of the efficient storage and processing of large volumes of information;
- a requirement for the multi-level metadata directories;
- increased data security requirements.
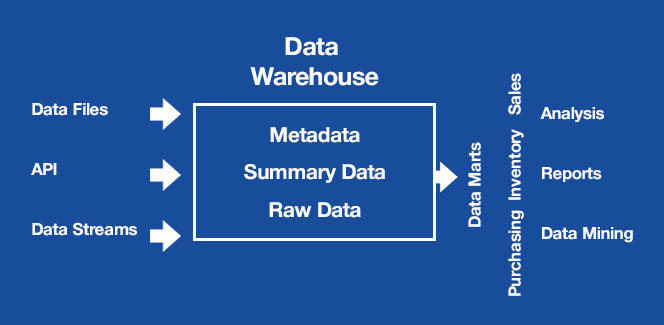
Also, data marts perform specific functions compared to the data warehouse as shown in Fig. 2.
Difference between database and data warehouse
- A database operates with current data whereas a data warehouse operates with historical data.
- A database is usually frequently updated. A data warehouse extracts data and evaluations to analysis and processing.
- A database is used for transactions whereas a data warehouse is used for analytical processing.
- Tables in a database are normalized whereas a data warehouse is optimized for faster querying.
- Analytical queries are faster on a data warehouse compared to a database.
- Database stores detailed data whereas a data warehouse stores summarized data.
- A database is oriented to a relational view whereas a data warehouse is oriented to a summarized multidimensional view.
- According to data warehouse concepts, database is designed for many concurrent transactions whereas a data warehouse is not effective in this area.
OLAP in the data warehouse
One of the important components of the data warehouse is the OLAP system, which helps the transition from two-dimensional data representation in databases to multidimensional representation.
OLAP (online analytical processing) is an interactive system that allows you to view different results on multidimensional data. The term "in real time" (online) means that new results are obtained in seconds, without a long wait for the result of the query.
The reason for using OLAP to process requests is speed. Relational databases store entities in separate tables, which are usually normalized. This structure is convenient for operational databases (OLTP systems), but complex multi-table queries are executed relatively slowly.
Then why do we need to compare the operational database vs. the data warehouse? Because operational databases are recommended to support high-volume transaction processing. And on the other hand, data warehousing systems are used for high-volume analytical processing.
In contrast to OLAP, databases store current transactions and enable fast access to specific transactions. This approach is known as Online Transaction Processing (OLTP).
Data warehouse tools
There are many data warehouse tools designed to build solutions in the field of data processing.
On-premises data warehouse tools:
IBM provides multiple data warehouse offerings, including on-premises, on cloud and as an integrated appliance. These include Integrated Analytics System, Db2 Warehouse and Db2 Warehouse on Cloud. Each product solves the specific needs of clients and provides high-quality solutions from IBM.
Autonomous Data Warehouse from Oracle is the first of many cloud services built on the next-generation, self-driving Autonomous Database technology. This service uses artificial intelligence to deliver unprecedented reliability, performance, and highly elastic data management that enables data warehouse deployment in seconds. Oracle uses the same Oracle Database software and technology that runs your existing on-premises.
Teradata Database provides the most powerful analytical engine with a rich set of advanced analytics. Another product Teradata IntelliBase allows building a compact environment for data warehousing and low-cost data storage.
Extract Transform Load or ETL processes and tools are essential for data warehousing. ETL allows moving data from sources to the data warehouse in a standard way quickly and reliably.
Most popular tools of ETL for data warehousing are the following:
- IBM InfoSphere DataStage
- Informatica Power Center
- Microsoft SSIS
- Oracle Data Integrator
Open source ETL tools:
- Apache Kafka
- Apache NiFi
- CloverETL
- Jaspersoft
- Pentaho Kettle
- Talend Open Studio
And as separate type are real-time ETL tools:
- Alooma
- Confluent
- StreamSets
- Striim
Cloud data warehouse
Since the data warehouse service is gaining popularity, the main providers of cloud systems have ensured their availability as a service on the network that can be easily scaled to fit your needs.
The main cloud data warehouses are:
- Amazon Redshift
- Google BigQuery
- Microsoft Azure SQL Data Warehouse
- Snowflake
Amazon Redshift
Amazon Redshift is a fast, scalable data warehouse, which makes it easier and more economical to analyze all data in the data warehouse and in the data lake. It uses machine learning technologies, massively-parallel execution of queries, and the columnar storage approach on high-performance drives. This provides a significant increase in data warehouse performance. It uses Amazon S3 storage and allows operation with terabytes of information in data warehouses.
Google BigQuery
The BigQuery service allows various hardware setup in the data warehouse. Google BigQuery allows users to download data, store it in tables, access data using SQL queries, and save and unload query results for further work. It allows the use of the concept of “everything in one place”, has great calculation speed and low cost for processing huge amounts of information. Plus it provides the ability to work online from any point and use fast visualization.
Microsoft Azure SQL Data Warehouse
This is a cloud-based corporate data warehouse (EDW), using mass-parallel processing (MPP) for fast execution of complex queries for several petabytes of data. Importing large quantities of data into the SQL data store takes place by using T-SQL PolyBase queries and it uses MPP capabilities to perform high-performance analytics.
Snowflake
Snowflake is an analytic data warehouse. It is provided as Software-as-a-Service (SaaS) that helps to minimize programming activities, time and budget. Snowflake's data warehouse uses Hadoop for implementation of distributed approach of data management and processing. Snowflake processes queries using “virtual warehouses” where each virtual warehouse is an MPP compute cluster.
Conclusion
In the dispute of data warehouse vs database we have to underline that both of them could clearly perform the same task, but, in fact, are designed for different applications. It could be extremely inefficient to try to solve the problem of performing a large number of transactions in data warehouses.
On the other hand, the presentation of information when using analytics should not be solved with the help of databases, data warehouses are a much superior tool.
Considering the database and data warehouse difference, a well-designed database and a properly crafted data warehouse will solve many problems and work quickly where it’s needed. Please contact Svitla Systems experts if you have the need to transfer your data from databases into data warehouses. Our specialists have a lot of experience with data warehouse and data lake technologies.
When choosing between a cloud data warehouse solution and your own servers, one needs to be guided by the cost of storing and processing data and the organization’s Internet bandwidth to ensure proper data transfer.



