
If Artificial Intelligence is the future, Machine Learning and Deep Learning are sure to be along for the ride. In this article, we explore and cover the concepts of deep learning vs machine learning, how they are different, how they are similar, and what’s in store for each of them.
What is deep learning?
As the concept of deep learning weaves itself into the business digital landscape, it’s important to identify how it differs from machine learning. For starters, deep learning is a subfield of machine learning, which in turn is a subfield of Artificial Intelligence. But what is deep learning at its core?
According to this piece from MathWorks, deep learning is “a machine learning technique that teaches computers to do what comes naturally to humans: learn by example.” This field essentially deals with tasks that typically require human intelligence and focuses on how to set up computers to learn by experience and acquire the necessary skills to reduce or eliminate human intervention.
As a subset of machine learning, deep learning uses artificial neural networks and algorithms that are designed to mimic human brain functions and process massive amounts of data. In fact, the word deep is used in the name to signify the numerous layers used in the neural network that facilitate the learning experience. By learning from experience, deep learning algorithms repeat tasks and tweak them as necessary and as many times as needed to improve the outcome.
Now, let’s talk about its parent field: machine learning.
What is machine learning?
Machine learning is, as we stated earlier, a subfield of the broader, all-encompassing concept of Artificial Intelligence. Machine learning is defined by SAS as a “method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.”
Machine learning stems from pattern recognition and the conjecture that computers are capable of learning without being programmed to perform specific tasks. In essence, artificial intelligence researchers became interested in the notion that computers could learn from the massive amounts of data that are available for analysis. The concept of machine learning is far more specific than that of artificial intelligence as it focuses on training machines to learn. One of the biggest, most well-known applications of machine learning so far is the use of this technique in Google’s self-driving car. This car embodies everything that machine learning is about: learning iteratively from exposure to new data and producing reliable, repeatable results.
Machine learning algorithms are designed to discover patterns in data to improve decision-making processes and make predictions. To do so, machine learning uses three widely recognized techniques: supervised learning, unsupervised learning, and reinforcement learning. We’ll cover these techniques along with a comparison of machine learning vs deep learning algorithms in a subsequent section.
Deep learning as part of the machine learning approach
Deep learning has its home within the realm of machine learning and has currently gained momentum with its techniques to classify, recognize, detect, describe, and ultimately understand complex sets of data. The data is transformed into knowledge that powers smart applications such as the Siri system embedded into iPhones, face recognition, language translation, etc.
While many consider that deep learning is still in the research phase to test the full range of capabilities it offers, it is already making an impact in numerous applications as part of the machine learning approach. Some of the most common uses of deep learning today include speech recognition and voice patterns, image recognition and automatic image captioning, natural language processing through the use of neural networks, and enhanced recommendation systems, like the one used by Netflix.
As part of the machine learning toolkit, deep learning is a remarkable technique to leverage and one that enables computers not simply to act and solve problems as instructed but instead, to solve the problem by themselves. As of late, deep learning replaces the creation of a data model with hierarchical layers that learn to recognize the inherent features of data, thus leading predictive systems into a far more sophisticated path that exceeds human performance.
The key to the success of the deep learning technique is the accuracy it offers through the use of neural network architectures. Nowadays, deep learning has been proven to outperform humans in tasks such as the classification of objects in images.
In essence, deep learning is a specialized practice of machine learning that performs end-to-end learning where raw data enters a network and is given a task which the system learns how to perform automatically. One of the key differentiators between machine learning and deep learning is that deep learning algorithms thrive as the size of data increases and feature extraction is automatic, which requires a high-performance GPU and large quantities of labeled data.
Next, we continue a comparison of machine learning vs deep learning algorithms to understand more about these two artificial intelligence subfields.
Comparison of machine learning vs deep learning algorithms
Machine learning algorithms, often with help from statistical models, should solve specific tasks without using explicit instructions. This is their main difference from traditional computer algorithms, which were used before the machine learning era. Let’s make a brief review of machine learning algorithms in the area of supervised, unsupervised and reinforcement machine learning.
Machine learning algorithms
Supervised machine learning
Supervised learning builds a model that makes predictions based on evidence. To develop these predictive models, it uses regression and classification techniques.
Linear Regression
Linear regression expresses a linear relationship between the input and the output.
Polynomial Regression
Same as linear regression, but it expresses a polynomial regression between input and the output. It gives a more precise result compared to linear regression.
Decision Trees
A decision tree is a series of nodes, a directional graph. This is for the predictions that result from a series of feature-based splits.
Random Forests
Random forests use many decision trees. They are an ensemble of decision trees. Each decision tree is created by using a subset of the attributes. Random forest is an effective supervised classification algorithm.
Classification
This set of algorithms includes the K-Nearest Neighbors Algorithm (KNN), Logistic Regression, Native-Bayes, Support Vector Machine (SVM), etc.
Unsupervised machine learning
Unsupervised learning discovers patterns in data by drawing conclusions from unlabeled input data.
Clustering
Algorithm clustering is K-means, which identifies the best k-cluster centers in an iterative form. Often a number of clusters are unknown.
Dimensionality reduction
Singular-Value Decomposition (SVD) is a matrix decomposition method for reducing a matrix to its constituent parts. Then the matrix has a smaller size and calculation can be accomplished faster for the given task. There are two approaches to dimensionality reduction. First is the feature selection: selecting from the existing features. Second is the feature extraction: extracting new features by combining the existing features. The main algorithm used for this task is Principle Component Analysis (PCA).
Association analysis
Many machine learning algorithms use Frequent Item Set (FIS) mining. It helps to extract the most frequent and largest item sets within big data sets. It is used for discovering relations between variables in large databases.
FP-tree algorithm counts the occurrences of items in the dataset of transactions. Then it builds the FP-tree structure by inserting transactions into a trie. In association analysis, for instance, AprioriDP algorithm utilizes Dynamic Programming in Frequent itemset mining.
Reinforcement Learning
This set of algorithms uses software agents to take actions in an environment to maximize values of cumulative reward. Usually, it includes the Markov decision process as well as the following algorithms:
- Criterion of optimality
- State-value function
- Brute force
- Monte Carlo methods
- Temporal difference methods
- Direct policy search
To show the advantages of each direction in machine learning, let’s take a look at this image from Sebastian Raschka, who provides probably the best explanation of how learning methods balance on each other.
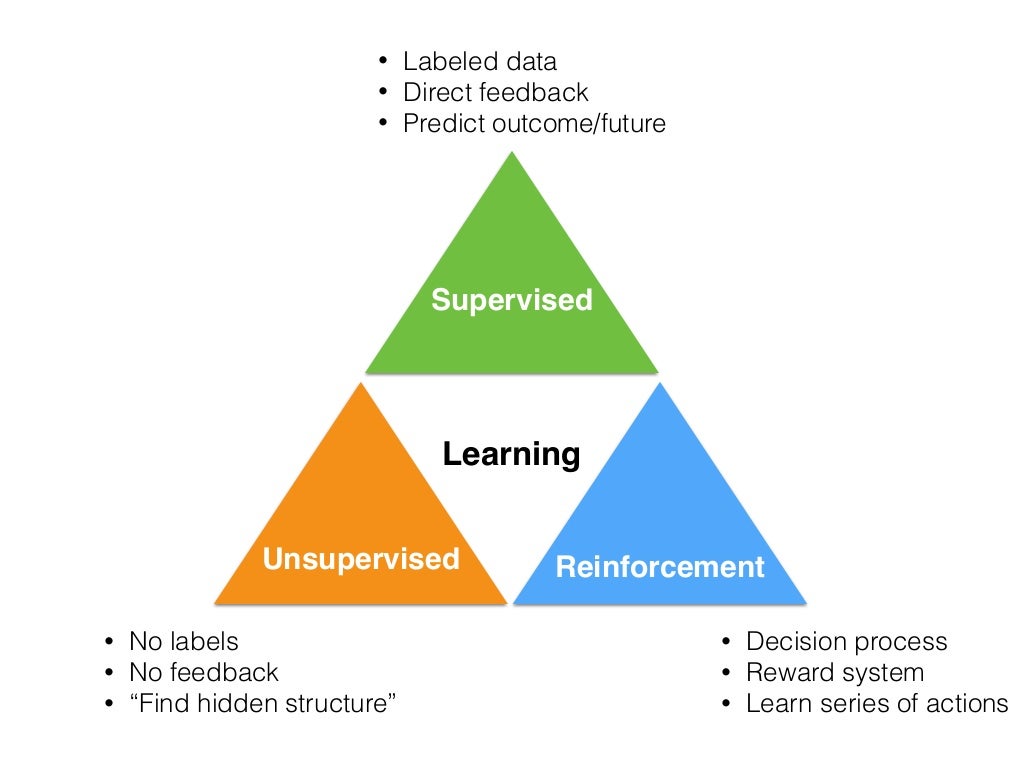
Image Source: https://www.slideshare.net/SebastianRaschka/nextgen-talk-022015/8-Learning_Labeled_data_Direct_feedback
Deep learning algorithms
Deep learning uses several “layers” of the artificial neural network, and step by step passes a representation of the data to the next layer. Each layer is connected to the next layer. By creating a proper activation function on the output of the math model of artificial neurons it is possible to find such values of the weight coefficient to “teach” a neural network to compute unbelievable results for complex tasks.
In the book “Fundamentals of Deep Learning: Designing Next-Generation Machine Intelligence Algorithms” Nikhil Buduma wrote: “Deep learning is a subset of a more general field of artificial intelligence called machine learning, which is predicated on this idea of learning from example. In machine learning, instead of teaching a computer a massive list of rules to solve the problem, we give it a model with which it can evaluate examples, and a small set of instructions to modify the model when it makes a mistake.”
To train or teach the model for a specific task the following algorithms can be used.
Back-Propagation
Back-propagation is commonly used by the gradient descent optimization algorithm to adjust the weight of neurons by computing the gradient to estimate loss function.
Stochastic Gradient Descent
Same method as classical gradient descent, but it uses randomly selected samples to evaluate the gradients.
Learning Rate Decay
In the neural network learning rate schedule changes the learning rate and is most often changed between epochs/iterations.
Dropout
Dropout is a regularization technique. Google patented it for reducing overfitting in neural networks. It prevents complex co-adaptations on training data. The term "dropout" refers to dropping out units (both hidden and visible) in a neural network.
Max Pooling
Convolutional networks may include some pooling layers to reduce the dimensions of between layers. Max pooling uses the maximum value from each of a cluster of neurons at the previous layer.
Batch Normalization
In a neural network, batch normalization is performed by a normalization step to fix the means and variances of each layer's inputs.
Long Short-Term Memory
Long Short-Term Memory (LSTM) has feedback connections in the neural network that make it a "general purpose computer" (the same as a Turing machine for instance). LSTM has a cell, an input gate, an output gate, and a forget gate. The cell remembers values and tree of gates regulate information flow in the network. This greatly expands the possibilities of using deep learning.
Transfer Learning
This technique helps to reuse existing knowledge in deep learning for solving similar related tasks with almost the same domain area.
Advantages of machine learning and deep learning
Machine learning will be effective in many business areas where you need to understand the relations of components in data and when it is necessary to explain and interpret the research results.
One of the main advantages of deep learning compared to other machine learning algorithms is the ability to effectively work with certain types of data, such as video, audio, and text information.
The deep learning algorithm will scan data for functions that correlate and combine them to provide faster learning without being explicitly specified.
In many cases, deep learning doesn’t require a process of feature engineering, which saves a lot of time and money. Also, it provides the possibility of solving problems in new areas, like generative neural networks, translation of foreign language with author (speaker) voice synthesis, etc.
| Machine Learning | Deep Learning |
| Parses data and adapts them to the specific task | Takes machine learning algorithm by neural networks |
| Provides a basement for deep learning as the next stage of AI | Can work with any kind of data, for instance, images, video, audio, text |
| Use network, graphs | Use neural networks |
| Need to have feature engineering | Need to have a set of marked training data |
Practical goals and objectives for machine learning and deep learning
Practical goals in machine learning and deep learning are driven by industries. They can be represented in the following categories:
- Computer vision: identification of vehicle license plate and identification.
- Control systems: stand-alone vehicles
- Obtaining information: search engines, both text search, and image search.
- Marketing: automated e-marketing, sales goal identification
- Medical diagnostics: identification of cancer, detection of anomalies
- Natural language processing: opinion analysis, photo tagging
- Internet advertising, recommendation systems
The outstanding results already obtained show that machine learning and deep learning will be in power for the next decades.
First and “game-changing”, IBM Deep Blue's victory over Garry Kasparov in chess was made in 1997.
In October 2015 AlphaGo from Alphabet beats human (Lee Sedol) in a Go game 19x19 board. This task for AI is about 10-100 times more complex than other board games.
IBM Watson is an AI system that is capable of answering questions in natural language. In 2011, the Watson computer system competed on the television game Jeopardy! against champions Brad Rutter and Ken Jennings, winning $1 million and first place.
A valuable recurrent neural network (RNN) driven breakthrough is where AI agents developed by Google’s DeepMind beat human pros at Starcraft II — a first in the world of artificial intelligence.
McKinsey claims that deep learning techniques potentially can create about $3.5-$5.8 trillion in value annually. Next steps for machine learning and deep learning will be in the area of everyday usage, for instance in smartphones, wearable devices, transportation, natural language communication with computers, etc.
Future of machine learning and deep learning
The trend of using machine learning and deep learning in the industry will become more important for every company that wants to survive in the modern environment.
Machine learning and deep learning surprise with progress every day and will continue to do so. This is due to the fact that Deep Learning is one of the best methods for the most advanced performance in complex tasks. In the near future, deep learning will create music, books, and visual art, as well as be helpful with many industries, including robotics, medicine, finance, education, agriculture, etc. The improving performance of specialized processors and hardware solutions will contribute to the rapid development of this area.
According to Yann LeCun, Director of AI Research at Facebook, deep learning combined with reasoning and planning is an area of research that is making promising advances. And there’s only more growth on the horizon for both subfields in addition to the breakthroughs that we’ve experienced so far.
At Svitla Systems, we have experience in machine learning and deep learning to help you utilize them most effectively. By keeping your company’s business and functional goals in mind, we prepare a strategy to help you navigate the ins and outs of both deep learning and machine learning, and execute the project according to your requirements and specific tasks.

FAQ
What is the fundamental difference between Deep Learning and Machine Learning?
The fundamental difference is that deep learning is a specialized subset of machine learning that utilizes artificial neural networks with multiple layers to automatically learn features from large datasets, often without human intervention. In contrast, traditional machine learning typically relies on algorithms that require manual feature engineering and can work with smaller datasets. Deep learning excels at handling complex data types, such as images, audio, and text. In contrast, machine learning is more general and often easier to interpret and implement for structured data and simpler tasks.
When should I use Deep Learning instead of traditional Machine Learning?
Consider deep learning if you have quite large volumes of data, more especially unstructured data such as images, audio, or natural language. Deep learning relies on automatic feature extraction and complex pattern recognition, outperforming traditional machine learning in areas such as speech recognition, image classification, and recommendation systems, particularly in tasks involving queries. Therefore, deep learning thrives well where the complexities of problem requirements render manual feature engineering infeasible and ineffective.
Does Deep Learning require more data than Machine Learning?
Deep learning, with its immense power, generally requires significantly more data than traditional machine learning to achieve optimal performance. Deep neural networks, with their numerous layers and parameters, need vast quantities of labeled data to learn complex patterns and generalize effectively. While machine learning algorithms can often perform effectively with smaller datasets, deep learning models truly shine and demonstrate their power when exposed to massive amounts of information.
What are some common applications of Deep Learning and Machine Learning?
Deep learning finds its major application in image recognition, speech recognition, natural language processing, automatic captioning, and advanced recommendation systems. Use cases of machine learning include predictive analytics and pattern recognition, in addition to medical diagnosis and fraud detection, as well as autonomous driving. Other applications include marketing automation and search engines – plus control systems – with deep learning for the more complex, data-heavy problem.


