

What is computer vision
Computer Vision is the theory and technology of creating machines that can detect, track, and classify objects.
As a scientific discipline, computer vision refers to the theory and technology of creating artificial systems that receive information in the form of images. Visual data can be presented in many forms, such as video sequences, images from different cameras, or 3D data from a medical scanner.
As a technological discipline, computer vision seeks to apply theories and models of computer vision to the creation of computer vision systems. Examples of such systems are:
- process control systems (industrial processes, autonomous vehicles)
- video surveillance systems
- information organization systems (i.e. for indexing image databases)
- object or environmental modeling systems (medical image analysis, topographic modeling)
- interaction systems (for example, input devices for human-machine interaction systems)
What is a digital image processing
Digital image processing is the use of computer algorithms for processing digital images. As an area of digital signal processing, digital image processing has many advantages over analog processing. It allows you to apply a much wider range of algorithms to the input data and to avoid problems such as added noise and distortion during processing. Since images are defined as two-dimensional (or higher), digital image processing can be modeled as multidimensional systems. The first digital image processing started in 1960 in areas such as satellite image and wire image transfer.
Modern computer vision tools
Modern software for computer vision includes libraries for programming, tools for working with neural networks and cloud solutions for performing tasks with images.
Let's look at the most popular tools that are now widely used in practice.
OpenCV
OpenCV (Open Source Computer Vision Library) is a library of functions and algorithms for computer vision, image processing, and numerical open source general-purpose algorithms. The library provides tools for processing and analyzing the content of images, including recognizing objects in digital photos (such as faces and figures of people, text, etc.), tracking the movement of objects, converting images, applying machine learning methods and identifying common elements in various images.
This library was originally developed at the Intel Software Development Center. OpenCV is written in a high-level language (C/C++) and contains algorithms for interpreting images, calibrating the camera according to a standard, eliminating optical distortions, determining similarities, analyzing the movement of an object, determining the shape of an object and tracking an object, 3D reconstruction, object segmentation, gesture recognition, etc. The library consists of the following components:
cxcore - core(contains basic data structures and algorithms):
- basic operations on multidimensional numeric arrays
- matrix algebra, mathematical functions, random number generators
- Write / restore data structures to / from XML
- basic functions of 2D graphics
CV - image processing and computer vision module
- basic operations on images (filtering, geometric transformations, color space conversion, etc.)
- image analysis (selection of distinguishing features, morphology, search for contours, histograms)
- motion analysis, tracking objects
- detection of objects, in particular persons
- camera calibration, spatial structure restoration elements
Highgui - a module for input/output of images and video, creating a user interface
- capture video from cameras and from video files, read/write static images.
- functions for organizing a simple UI (all demo applications use HighGUI)
Cvaux - experimental and legacy features
- spaces. Vision: stereo calibration, self-calibration
- search for stereo matching
- finding and description of facial features
Tensorflow
This is the most popular machine learning and deep learning library today. its popularity rapidly increased and surpassed existing libraries due to the simplicity of the API. Google released it in November 2015.
It is written in Python, but now there is also a JavaScript port (tensorflow.js). This addition is due to the growing popularity of JavaScript after the release of Node.js.
TensorFlow is a free open-source library for data streams and differential programming. It is a symbolic math library that is also used for machine learning applications such as neural networks.
In TensorFlow 2.0, by default, Eager execution is used as the model execution mode. That is, the calculation of specific values occurs along the way, to build a complete computing graph. This simplifies model debugging and eliminates the need for boilerplate code.
You can use standard Python structures as data structures. You can quickly test hypotheses and easily debug code on small models and small amounts of data. Eager execution also supports GPU acceleration and distributed computing on many machines.
TensorFlow 2.0 facilitates the implementation of pre-trained models that are tuned for image and speech recognition, object detection, recommendations, reinforced learning, etc. Such reference models allow you to use best practices out of the box and serve as starting points for developing your own high-performance solutions.
CUDA
CUDA (Compute Unified Device Architecture) is a parallel-computing hardware and software architecture that can dramatically increase computing performance through the use of Nvidia GPUs.
The CUDA SDK provides the ability to include C call routines running on Nvidia GPUs in C text. This is done through commands written in special dialect C. The CUDA architecture gives the developer the ability, at their discretion, to access and manipulate the graphics accelerator instruction set.
The original version of the CUDA SDK was introduced on February 15, 2007. The CUDA API is based on C language.
With CUDA acceleration, applications can achieve interactive video frame-rate performance.
- Level-Set segmentation with CUDA
- Video segmentation with CUDA
- Multiclass SVM implementation in CUDA
- Pedestrian Detection
- Flowlib: Dense Optical Flow
- Bayesian Optical Flow
- Machine-learning & data processing
- Hardware Efficient Belief Propagation
- Fast k-nearest neighbor search using GPU
Using CUDA, computer vision tasks can be solved faster and technologies reach a new level; for example, the ability to automatically control vehicles, process large volumes of photo and video information, process medical video data, and so on.
Theano
Theano is a fast Python numerical library that can run on a CPU or GPU. It was developed by the LISA team (now MILA) at the University of Montreal in Canada. Theano is an optimizing compiler for manipulating and evaluating mathematical expressions, especially matrix-valued ones.
Here are the key methods, operations, and data structures supported by Theano:
- tensors through the numpy.ndarray structure and support for many tensor operations
- sparse matrices through scipy. {csc, csr, bsr} _matrix structures and support of a number of operations with them
- the ability to create new operations with graphs in the operating mode
- numerous graph conversion operations
- Python language support for versions 2 and 3
- GPU support (CUDA and OpenCL)
- Basic Linear Algebra Subprograms (BLAS) standard support for linear algebra procedures
Keras
Keras is a deep learning Python library that combines the functions of other libraries, such as Tensorflow, Theano, and CNTK. Keras has an advantage over competitors such as Scikit-learn and PyTorch, as it runs on top of Tensorflow.
Keras can run on top of TensorFlow, Microsoft Cognitive Toolkit, Theano, or PlaidML. Designed for quick experimentation with deep neural networks, it focuses on usability, modularity, and extensibility.
Keras is an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs and minimizes the number of user actions required for common use cases.
Scikit-learn
This popular machine learning library is built on NumPy, SciPy, and matplotlib. It focuses on ML algorithms:
- Supervised learning
- Unsupervised learning
- Linear regression
- Logistic Regression
- Support-vector machine (SVM)
- Naive Bayes Classifier
- Gradient Boost
- Clustering
- K-means method
This library is less developed than Tensorflow, however, it provides simple and effective tools for data discovery and analysis.
YOLO
“You only look once” or YOLO is an object detection system designed especially for real-time processing. YOLO is an advanced real-time object detection system developed by Joseph Redmon and Ali Farhadi from the University of Washington. On their website, you can find SSD300, SSD500, YOLOv2 and Tiny YOLO implementation. Their algorithm applies a neural network to an entire image and the neural network divides the image into a grid and marks regions with detected objects.
- Very fast and good performance for real-time processing.
- Predictions are made from one single network.
- YOLO is generalized. It outperforms other methods when generalizing from natural images.
- Region proposal methods limit the classifier to the specific region. YOLO accesses to the whole image in predicting boundaries.
- YOLO detects one object per grid cell.
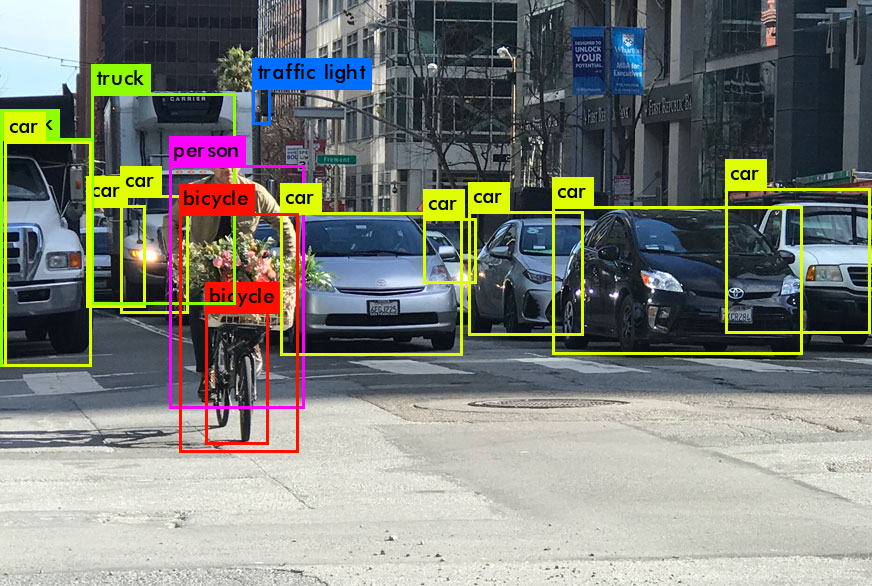
Fig. 1. YOLO object detection.
Image source
Cloud-based computer vision tools
Google Cloud and Mobile Vision APIs
Google provides AutoML Vision as a cloud service. It allows automating the training of your own custom machine learning models. It is necessary to upload images and train custom image models with AutoML Vision’s easy-to-use graphical interface. AutoML allows optimizing your models for accuracy, latency, and size; and exporting them to your application in the cloud, or to an array of devices.
Google Cloud’s Vision API offers powerful pre-trained machine learning models through REST and RPC APIs. It assigns labels to images and quickly classifies them into millions of predefined categories. Google Vision API allows us to detect objects and faces, read printed and handwritten text, and build valuable metadata into an image catalog.
Google Cloud’s Vision API allows developers to analyze images and contextual data using self-learning and evolving machine learning models ин a simple REST API. We can obtain contextual information about an image and classify images into categories and subcategories, achieving a deep level of detail of information. Let's take a look at the most interesting features of Google Cloud’s Vision API:
- Tag detection (detect categories within an image).
- Explicit Content Detection (recognise indecent or violent content in an image).
- Recognition of popular logos.
- Recognition of geographical landmarks: (natural and artificial structures).
- Optical character recognition (detection and extraction of text inside the image, the API recognizes the language of the text).
- Face Recognition (detects multiple faces within an image, as well as other attributes).
- Image Attributes (detection of common image attributes such as dominant colors).
Amazon Rekognition
Amazon Rekognition lets you easily embed in-app image and video analytics with deep learning. The service can recognize objects, people, text, scenes, and actions, as well as detect inappropriate content. In addition, Amazon Rekognition accurately analyzes and recognizes faces in customer images and videos. Amazon Rekognition is based on accurate, scalable deep learning technology. Amazon Rekognition is a simple API that quickly parses any images and videos stored in Amazon S3.
Pre-trained algorithms
- Celebrity recognition in images
- Facial attribute detection in images, including gender, age range, emotions
- People's Pathing enables tracking of people through a video. An advertised use of this capability is to track sports players for post-game analysis.
- Text detection and classification in images
- Unsafe visual content detection
Algorithms that a user can train on a custom dataset:
- SearchFaces enables users to import a database of images with pre-labeled faces, to train a machine learning model on this database, and to expose the model as a cloud service with an API.
- Face-based user verification
Microsoft Azure Computer Vision API
This state-of-the-art cloud-based API allows developers to use sophisticated algorithms to extract valuable information from images to classify and process visual data. Azure's Computer Vision service provides developers with access to advanced algorithms that process images and return information. It is possible to use Computer Vision by using either a native SDK or invoking the REST API directly:
- Tag visual features
- Detect objects
- Categorize an image
- Describe an image
- Detect faces
- Detect image types
- Detect domain-specific content
- Get the area of interest
- Extract text from images
- Moderate content in images
- Real-time video analysis
One of the advantages of this cloud system is its flexible pricing policy, including free test access.
Conclusion
In conclusion, we can say that now image processing and computer vision are no longer exotic or highly specialized industries in computer systems. More and more often we will use these methods in a very wide range of products.
And more and more developers will use libraries and cloud solutions in mobile applications, smart home systems, the Internet of things, and transport systems. Cloud solutions provide you with the ability to work with well-trained and powerful computing resources, while client frameworks and libraries give you the opportunity to process these solutions directly on the device, without the need to access the Internet.



