

If you are building a successful startup or doing an interesting outsourcing project, and you have the task of indexing and ranking documents, then you can use a ready-made open-source library to solve this problem.
Naturally, the first thing that comes to mind is to quickly use ElasticSearch. If you have no practical experience working with such a library or the number of documents for indexing is not significantly large, then you can connect to the Whoosh library in just a few minutes. One of the advantages of using this library is the availability of an interface in Python to Whoosh.
Let's take a look at how quickly you can write a small API using Whoosh and a simple Flask library to handle network requests.
Please note that Whoosh library is an open-source project and the latest version updated was back in 2019. This library works well, but it is not a replacement for ElasticSearch for large scale projects, as it’s designed purely to fulfill specific problems posed to it.
What is the searching and ranking of documents?
Formally, search or information retrieval is the process of searching for unstructured documentary information.
Information search is the process of identifying in a set of documents, for example, in the form of texts, all those that are devoted to a specified topic or subject, satisfy a predetermined search condition (that is, a query) or contain the necessary facts, information, data corresponding to the information needed.
The search process includes a sequence of operations aimed at collecting, processing and providing information.
Ranking (assess, distribute) is a list of any objects (for example, people or companies), which is ordered according to one of the selected ranking indicators. Unlike a rating, which is a fixed list, a ranking is a database to which various parameters and ranking methods can be applied.
All indicators used in the ranking are digital. Data can be of the economic, natural or statistical kind for the companies of interest. The ranking can be used in any area where it becomes necessary to arrange the list of companies, offers, participants, etc. by a numeric parameter.
As mentioned in the Whoosh documentation: “Whoosh is a fast, featureful full-text indexing and searching library implemented in pure Python. Programmers can use it to easily add search functionality to their applications and websites. Every part of how Whoosh works can be extended or replaced to meet your needs exactly.”
Some of Whoosh’s features include:
- Pythonic API.
- Pure-Python. No compilation or binary packages needed without mysterious crashes.
- Fielded indexing and search.
- Fast indexing and retrieval – faster than any other pure-Python, scoring, full-text search known solution.
- Pluggable scoring algorithm (including BM25F), text analysis, storage, posting format, etc.
- Powerful query language.
- Pure Python spell-checker.
Another interesting aspect of this library is its ability to support various algorithms, for instance, BM25F. Okapi BM25 is a ranking function used by search engines to estimate the relevance of documents to a given search query. It is based on the probabilistic retrieval framework developed in the 1970-80s by Stephen E. Robertson and Karen Spärck Jones.
BM25 and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval. BM25F is a modification of BM25 in which the document is considered to be composed of several fields. These fields could be headlines, main text, anchor text with possible different degrees of importance, term relevance saturation, and length normalization.
Installing Whoosh library
There’s not a lot you need to do on your end to install the Whoosh library, as well as other libraries for Python. If you have pip installed, then downloading the Whoosh library will not take much time, and it can be done with a single command.
pip install whoosh
If you don't have pip on your system, please refer to the following document to install it. This is also a fairly simple and fairly short process. Once pip is installed, you can easily load it on the Python command line (or in a Python file). You can validate if Whoosh is correctly configured by simply typing:
$ python3
Python 3.9.4 (v3.9.4:1f2e3088f3, Apr 4 2021, 12:32:44)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import whoosh
>>>
Code language: JavaScript (javascript)From the results above, you can tell that Python version 3 works correctly with the Whoosh library.
Add documents to the indexing database
To add documents to the indexing database, there are some simple and effective calls you can make to the Whoosh library.
First of all, you need to create a schema of the indexing document.
schema = Schema(path=ID(stored=True, unique=True), content=TEXT, doc=STORED)
Code language: PHP (php)Next, create a directory for binary indexing files.
writer = ix.writer()
writer.add_document(path=str(myid), content=mycontent, doc=mycontent)
writer.commit()
Where myid is the ID of the document and mycontent is a text of documents.
Simultaneously, you can add different data types to the schema, as described in the Whoosh documentation:
- whoosh.fields.TEXT - This type is for body text. It indexes (and optionally stores) the text and stores term positions to allow phrase searching.
- whoosh.fields.KEYWORD - This field type is designed for space- or comma-separated keywords. This type is indexed and searchable (and optionally stored).
- whoosh.fields.ID - The ID field type simply indexes (and optionally stores) the entire value of the field.
- whoosh.fields.STORED - This field is stored with the document, but not indexed and not searchable.
- whoosh.fields.NUMERIC - This field stores int, long, or floating-point numbers in a compact, sortable format.
- whoosh.fields.DATETIME - This field stores datetime objects in a compact, sortable format.
- whoosh.fields.BOOLEAN - This simple field indexes boolean values and allows users to search for yes, no, true, false, 1, 0, t or f.
The full text of the code for the ADD method of your API may look like this (we will also use the Fask library to handle HTTP requests):
import os
import sys
from flask import Flask
from flask import request, jsonify
from flask_json import FlaskJSON, JsonError, json_response, as_json
from whoosh.index import create_in
from whoosh.index import open_dir
from whoosh.fields import *
from whoosh.qparser import QueryParser
from whoosh.qparser import MultifieldParser
from whoosh.query import Every
@app.route('/add', methods=['POST'])
def add():
try:
data = request.get_json(force=True)
schema = Schema(path=ID(stored=True, unique=True), content=TEXT, doc=STORED)
try:
os.mkdir('indexdir')
ix = create_in("indexdir", schema)
except:
print("indexdir already exists")
ix = open_dir('indexdir')
writer = ix.writer()
content = data['content'] # content of the document
myid = data['id'] # id of the document
writer.add_document(path=str(myid), content=content, doc=content)
writer.commit()
return json_response(status_=200, data=content, id=myid)
except:
raise JsonError(description='Invalid add request.')
Code language: PHP (php)Make search and ranking requests
To organize a search in an indexed document base, you can use the QueryParser for your indexing scheme, which we built in the previous version.
query = QueryParser("content", ix.schema).parse(search_str)
Code language: JavaScript (javascript)Where search_str is your string to make a request to a stored indexed document database.
Then, according to the already constructed query, you can get a list of ranking documents, in descending order of rating. In this case, we will take 20 of these types of documents.
results = searcher.search(query, terms=True, limit=20)
Code language: PHP (php)Next, the search query processing through the API full text will look something like this.
@app.route('/search', methods=['GET'])
def search():
try:
data = request.get_json(force=True)
search_str = data['search']
ix = open_dir('indexdir')
with ix.searcher() as searcher:
query = QueryParser("content", ix.schema).parse(search_str)
results = searcher.search(query, terms=True, limit=20)
res_str = ""
score_str = ""
content = ""
for r in results:
res_str += str(r.values()[1])
content += str(r.values()[0])
score_str += str(r.score)
if r != results[-1]:
res_str += ' '
score_str += ' '
content += ' '
return json_response(status_=200, search=data['search'], id=res_str, score=score_str, content=content)
except:
raise JsonError(description='Invalid search request.')
Code language: PHP (php)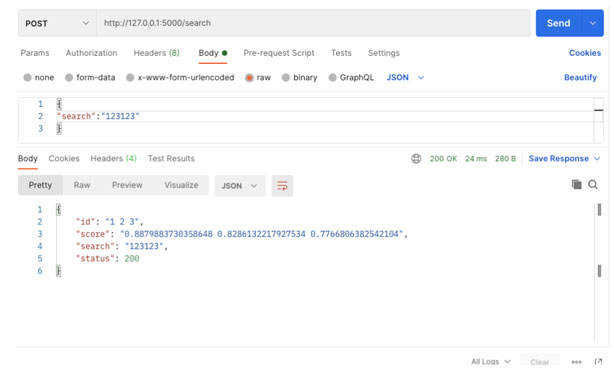
Accordingly, the search results will come to you in the form of a JSON file. For instance, for the given request, three documents were found.
Updating documents from the database
To update documents to the database, Whoosh allows changing existing indexed documents. It can be done with this function:
writer.update_document(path=str(myid), content=content, doc=content)
Of course, in the Flask library, we will change the endpoint to /update and the HTTP method will be PUT.
@app.route('/update', methods=['PUT'])
def add():
try:
data = request.get_json(force=True)
print (data)
schema = Schema(path=ID(stored=True, unique=True), content=TEXT, doc=STORED)
print (schema)
try:
os.mkdir('indexdir')
ix = create_in("indexdir", schema)
except:
print("indexdir already exists")
ix = open_dir('indexdir')
writer = ix.writer()
content = data['content']
myid = data['id']
print (id)
print (content)
writer.update_document(path=str(myid), content=content, doc=content)
writer.commit()
return json_response(status_=200, data=content, id=myid)
except:
raise JsonError(description='Invalid add request.')
Code language: PHP (php)Deleting documents from the database
If necessary, you can delete a document from the indexing databases. To do so, you can use:
res = writer.delete_by_term('path', id)
Code language: JavaScript (javascript)The API method will look like this:
@app.route('/delete', methods=['delete'])
def delete():
try:
data = request.get_json(force=True)
ix = open_dir('indexdir')
writer = ix.writer()
id = str(data['id'])
res = writer.delete_by_term('path', id)
writer.commit()
return json_response(status_=200, result=res)
except:
raise JsonError(description='Invalid delete request.')
Code language: JavaScript (javascript)The JSON file with line result=1 will be returned if the document is deleted from the indexing database.
This example is very simple and was created for demo purposes only. Whoosh allows you to create more complex Shema and make the search for ranking documents for complex requests with multiple fields. Please refer to the following documentation about Whoosh.
Conclusion
The Whoosh library is a great search and ranking engine. This library is a wonderful tool in the right hands. It might be useful in the following circumstances:
- Anytime a pure-Python solution is desirable to avoid having to build/compile native libraries (or force users to build/compile them).
- As a research platform (at least for programmers that find Python easier to read and work with than Java).
- When an easy-to-use Pythonic interface is more important to you than raw speed.
We figured out how quickly and with how much effort you can rank documents. In addition, the Flask library allows you to do this in the form of a simple and convenient API. If you are going to perform document ranking on large scales, you can refer to the ElasticSearch library in the future.
Our Svitla Systems specialists will ensure you receive a high-quality and reliable implementation of information technology projects. Our experts have a wealth of experience in software development across various application industries including Python and other languages/frameworks, as well as being very well-versed in the heavy use of ElasticSearch.
Svitla Systems provides services in software testing, cloud solutions, DevOps, and much more. We help build applications for mobile devices from scratch. Connect with our leading sales and systems analysts who work with senior engineers and testers to help you complete your project, regardless if you’re looking for a startup or enterprise-grade solution, there’s the right mix of Svitla Systems resources for your unique project needs.



