

Very often a situation arises when you need to quickly take information from a web page, usually numerical data and most likely presented in the form of tables.
This happens in private applications, but also in companies. A task of this type is always unscheduled, since if it was anticipated the data would be taken from the web page through the API provided by the site of the information provider.
The time-sensitivity of such a task usually fluctuates around a couple of hours, or 1-2 business days, or a maximum of a week, but the information that we receive from the web page of a third-party site is very important just at that moment. "A stitch in time saves nine."
Options for accessing information on the network
There are two ways to access the latest information on the Internet.
The first is through the API that media sites provide, and the second is through site parsing (Web Scraping).
Using the API is extremely simple, and probably the best way to get updated information is to call the appropriate program interface. But, unfortunately, not all sites provide public APIs or you simply do not have enough time to take data through the API. Under this circumstance, there is another way and this is parsing the web page.
There are three main steps to getting information from a web page (Fig. 1).
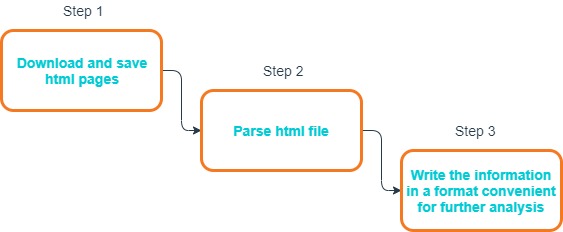
The sequence of actions for obtaining information from a web page will correspond to the steps in the previous section and in general terms looks like this:
- get the URL of the page from which we want to extract data.
- copy or download the HTML content of the page.
- parse the HTML content and get the necessary data.
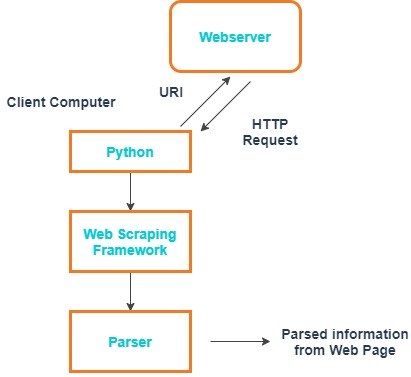
This sequence helps you to go to the URL of the desired page, get HTML content and analyze the necessary data (Fig. 2). But sometimes you need to first enter the site, and then go to a specific address to get the data. In this case, one more step is added to enter the site.
Fig. 2. Structure diagram for getting information from web pages in Python
Why it can be easily done in Python
Why does this problem need to be solved in Python? Undoubtedly, there are other solutions using other programming languages. However, there are some significant advantages when you use Python:
- Python is an interpreter language, you do not need to compile code
- Python and its associated packages are free
- The entry threshold is quite low, you can figure it out in 30-40 minutes
- Python works well on Linux, MacOS, and Windows
- There are already ready-made solutions, you do not need to reinvent the wheel, just adjust it to your needs
Packages for Python
To analyze the HTML content and obtain the necessary data, the simplest way is to use the BeautifulSoup library. This is an amazing Python package for parsing HTML and XML documents.
You can also use the Selenium library to enter the website, navigate to the desired URL in one session and download the HTML content. Selenium Python helps with button clicks, content entry, and other manipulations.
You can use the lxml library. It works very fast, but there are many limitations. To avoid determining the entry to the page using a robot program, you need to emulate the browser of a regular user.
The Grab framework can pretend to be a regular user with all sorts of user agents and cookies. This package is easy to learn, but you will have to delve into its documentation.
There are many Python libraries for sending http requests, the most famous being urllib/urllib2 and Requests. Requests are generally considered more convenient and concise.
The following are more details about BeautifulSoup as well as other options for a library to parse html.
BeautifulSoup, lxml
These are the two most popular libraries for html parsing and the choice of one of them is likely. Moreover, these libraries are closely intertwined: BeautifulSoup began using lxml as an internal parser for acceleration, and the soupparser module was added to lxml. You can read more about the pros and cons of these libraries in the documentation and on Stackoverflow.
BeautifulSoup is a library for parsing HTML/XML files, written in the Python programming language, which can even convert incorrect markup to a parsing tree. It supports simple and natural ways to navigate, search, and modify the parsing tree. In most cases, it will help the programmer save hours and days of work.
BeautifulSoup allows you to work with unicode, which opens up great opportunities for processing pages in different languages.
In general, the library is so well built and structured that it allows you to quickly take the page and get the necessary information. The library’s functionality is represented by the following main sections:
- Parsing Tree Navigation
- Search the parsing tree
- Search inside the parsing tree
- Modify the parsing tree
Lxml is a great library to use with BeautifulSoup for parsing files with tree structure and it supports ElementTree API. This library provides binding for the C libraries libxml2 and libxslt.
Scrapy
Scrapy is not just a library, but an entire open-source framework for retrieving data from web pages. It has many useful functions: asynchronous queries, the ability to use XPath and CSS selectors for data processing, convenient work with encodings and much more.
Scrapy is a great tool for both simple site parsing and complex solutions. Its structure is very clear and intuitive. It is fast (thanks to Twisted) and very easy to extend. It provides many examples and ready-to-use extensions. Scrapy is one of the best tools in its class.
Scrapy is mainly designed for web scraping, but it can also be used to extract data using APIs.
Grab
Grab is a library for working with network documents. The main areas where f Grab is useful are:
- data extraction from websites (site scraping)
- work with network APIs
- automation of work with websites, for example, a profile registrar on a website
Grab consists of two parts:
- The main Grab interface for creating a network request and working with its result. This interface is convenient to use in simple scripts where you do not need a lot of multithreading, or directly in the Python console.
- Spider interface for developing asynchronous parsers. Firstly, this interface allows a more strict description in the logic of the parser, and secondly, the development of parsers with a large number of network streams.
Requests library
The Requests library is an effective library for importing data from web pages. It allows making HTTP requests, which means you can use it to access web pages. Requests library has the following advantages:
- Thread-safe
- Manages Connection Timeouts
- Key/Value Cookies & Sessions with Cookie Persistence
- Automatic Decompression
- Basic/Digest Authentication
- Browser-style SSL Verification
- Works with restful API, i.e., all its methods – PUT, GET, DELETE, POST.
But Requests library is not recommended if the web page has Javascript hiding or loading content.
urllib/urllib2
Urllib2 is a Python module that helps you work with a URL. The module has its own functions and classes that help in working with URLs - basic and digest authentication, redirects, cookies, and much more.
This library is extensive. It supports basic and digest authentication, redirections, cookies and more.
While both modules are designed to work with URLs, they have different functionality.
Urllib2 can take a Request object as an argument to add headers to the request and more, while urllib can only accept a string URL.
Urllib has a urlencode method that is used to encode a string into a view that satisfies the data rules in the queries.
This is why urllib and urllib2 are used together very often.
Parsing
XPath is a query language for xml and xhtml documents. It is most commonly used when working with the lxml library.
XPath (XML Path Language) is a query language for elements of an XML document. It is designed to provide access to parts of an XML document in XSLT transformation files and is a standard of the W3C consortium. XPath aims to implement DOM navigation in XML. XPath uses compact syntax other than XML.
Like SQL, XPath is a declarative query language. To get the data of interest, you just need to create a query that describes the data.
lxml is the most feature-rich and easy-to-use library for processing XML and HTML in Python.
Another powerful library for parsing is regular expression (re). With regular expressions, you can do anything at all. Literally everything. You can parse any information from a web page, you can do preprocessing and many more tasty options.
Regular expressions will come in handy, of course, but only using them is probably a bit too hardcore, and not what they are designed for.
It is very important to correctly write the parser, since quite often the information presented on the page is not in the form of a table, but in the form of certain HTML tags, making it more difficult to structure and correctly parse information from the page.
Start updating information at a specific time
If we parse a website that frequently updates content, for example, competition results or current results for some informational event, it is advisable to create a cron task to run this program at specific time intervals.
The tqdm library shows the progress of any cycle. You just need to wrap it and the console will see progress. It is used just for clarity, but it helps a lot when the process is not fast.
Is it possible to do this without Python at all?
Yes, it is possible. You just need to find the right cloud service where such a system is already created; then, without any problems, you can configure the parsing of the web page you need there and everything will work fine. For example, you can choose from the following cloud services, according to your taste and needs.
Import.io offers the developer an easy way to create their own data packets: you only need to import information from a specific web page and export it to CSV. You can extract thousands of web pages in minutes without writing a single line of code, and create thousands of APIs according to your requirements.
Webhose.io provides real-time direct access to structured data obtained by parsing thousands of online sources. This parser is able to collect web data in more than 240 languages and save the results in various formats, including XML, JSON, and RSS.
Scrapinghub is a cloud-based data parsing tool that helps you select and collect the necessary data for any purpose. Scrapinghub uses Crawlera, a smart proxy rotator equipped with mechanisms that can bypass the protection against bots. The service is able to cope with huge volumes of information and sites protected from robots.
In addition, Google Spreadsheet tables allow you to import data from web pages and can be very convenient.
Conclusions
In general, we can say that this approach is quite workable. But do not abuse this method, it is better practice to use the API to get information from the website. But as a temporary solution to a time sensitive problem, this system, works and is more efficient than just copying the data manually.
Pay attention to the BeautifulSoup library, use the Selenium browser with the necessary plug-ins from Python, and use the Panda. If necessary, just activate the necessary ready-made cloud service.
Good luck with your projects and easy work on Python.



