

Machine learning (ML) has emerged as a transformative force in the modern banking landscape. Algorithms can recognize correlations in data at a speed and scale, unfathomable for a human analyst.
Because lending requires meticulous data analysis, ML has a solid potential to have a measurable impact on your operations. In this post, we’ll cover the advantages of using machine learning for credit scoring and the types of algorithms effectively applied in the financial sector.
How Can Machine Learning Revolutionize Credit Scoring?
Accurate, multi-dimensional analysis is key to effective credit assessments. Machine learning algorithms can bring greater speed, accuracy, precision, and fairness to leading decisions.
Improve Credit Access
Traditional credit models exclude a large fraction of the global population – credit invisible and credit thin consumers. In the US, over 45 million consumers are considered either credit unserved or credit underserviced, according to TransUnion. In other countries, even fewer people are visible to local credit bureaus.
The percentage of unserved consumers is as follows:
- India – 63%
- South Africa – 51%
- Columbia – 44%
- Hong Kong - 16%
Machine learning models can help companies bring more data into the underwriting and make more accurate lending decisions without increasing operational risks.
Increase Accuracy of Assessments
In NY, USA, the overall rejection rate for loan applications increased to 21.8% in June 2023 – the highest rejection rate since June 2018. In the current economic climate, banks are wary of lending money.
Machine learning algorithms can help build a more accurate picture of a borrower’s creditworthiness. Apart from analyzing the traditional parameters such as “debt-to-income ratio” or “employment stability models”, such models can take into account broader factors like “regulatory of rent payments” or “earning history from gig platforms”.
In the UK, 7 in 10 gig workers have been denied access to financial products such as a loan, despite having and maintaining a good credit score. ML lending solutions can help score consumers with multiple income streams and untraditional careers more accurately.
Drive Operational Performance
Financial institutions still increasingly rely on manual credit risk assessments for loan underwriting. As a result, many struggle to achieve consistent quality and high operational performance.
Source: McKinsey
New technologies like big data analytics and machine learning among others empower underwriting teams to deliver better customer service levels and, by proxy, higher operational returns.
According to an Accenture survey, technology has already helped underwriting teams increase speed to quote (60%), manage large amounts of business (59%), and access more knowledge (58%).
Traditional Credit Scoring Approaches vs. Credit Scoring With Machine Learning
Traditional credit scoring models rely on historical credit data and pre-defined rules. The system discards an application when a borrower’s history doesn’t match up.
In contrast, machine learning credit scoring systems use traditional data (like aggregated credit scores) and alternative data (e.g., rental payments, mobile data, etc.) to identify borrower behavior patterns. Machine learning uses these learned patterns to predict the likelihood of different credit risks.
By analyzing more data, ML-based credit scoring models present a more holistic picture of the applicant’s financial behavior, showing aspects traditional methods might miss. Such models also help eliminate the advisors’ biases about the applicant’s age, gender, profession, employment status, or ethical background.
Here’s a summary of the main differences between traditional credit scoring vs. ML-based credit scoring:
Data Sources
Traditional scoring models mostly use data from credit reporting agencies Equifax, Experian, and TransUnion. Credit models like FICO Score and VantageScore use historical data from agencies to generate a custom score for the borrower, which banks then use to make credit decisions.
In other countries, where credit scoring isn’t as popular, banks use rule-based loan origination systems. Traditionally, such systems use a limited number of data sources (e.g., transactional data, lending history, employment records, etc) to assess borrowers. The total number of assessment criteria hoovers at 10 to 20 parameters.
ML-based credit models use more data sources and data types. Alternative credit card data includes:
- Rent and utility payments
- Cashflow trends
- Checking account information
- Mobile data and mobile payments
- Telecom and Internet data
FinTech lender SoFi, for example, has been using machine learning in credit scoring to factor in the applicants’ educational attainment, utility payments, insurance claims, and mobile phone usage, among others. By combining alternative data sources with predictive scoring models, SoFi launched a portfolio of innovative lending products (student loans, home loans, personal loans, and credit cards). In Q2 of 2023 alone, SoFi added over 584K new customers, bringing the total to over 6.2 million. The company’s revenue for the twelve months ending June 30, 2023, was $2.304B, a 71.94% increase year-over-year.
Decision Speed
Because most of the steps in the loan underwriting process are manual, traditional financial institutions need more time for decision-making. On average, closing a home loan takes 35 to 40 days.
On average, FinTech lenders, process mortgage applications about 20% faster than traditional institutions by using a smart combination of automation and predictive analytics for risk assessments.
Digital lenders automatically source data with Open Banking via financial APIs. Instead of requesting paper documents and endless signed forms, lenders can automatically access and verify the borrower’s income, employment, and asset ownership by securely accessing data from their bank account or payroll provider.
Automatic access to information increases data collection speed and accuracy, plus reduces error rates. New Know Your Customer (KYC) solutions also make digitally verifying the lenders’ identity and background easier. Once all the data is collected, a machine learning algorithm can individually score each applicant and present a recommendation summary for the underwriter.
By automating loan origination, lenders can grant decisions faster without skimming on due diligence. Small business lender, Kabbage (acquired by AmEx), said that 95% of its customers received a fully-automated underwriting experience, resulting in faster customer acquisition.
Default Rates
Every bank has time-bound quantitative non-performing loan (NPL) targets. A good NPL to total asset ratio averages at about 4%. When the ratio inevitably increases during harder economic times, most banks respond with lending freezes, especially for credit-thin consumers.
Such NLP strategies, however, don’t address the underlying problem—poor initial evaluations. By combining big data and machine learning, banks can better predict loss rates on a case-by-case basis. Chinese digital banks WeBank, MYBank, and XWbank, issue over 10 million loans annually while maintaining an NPL of 1% on average.
Analysis Methods
Traditional credit scoring models use statistical, rule-based methods for credit evaluations. These are mostly based on the applicant’s credit history (e.g., percentage of on-time payments, total number of opened credit accounts, etc). In addition, most advisors rely on in-person applicant interviews and subsequent discretionary judgments to make the decision. As a result, many applicants face unfair treatment. In the US, mortgage seekers from minority groups are charged 8% higher interest rates and get rejected for home loans 14% more frequently.
In contrast, machine learning models employ a wider range of data points and evaluation algorithms to make objective, data-based decisions. For example, Argentinian business lender Mercado Libre uses some 2,400 behavioral variables for scoring each applicant. To make fair evaluations, each group of factors has different weights, for example, the applicant’s past sales history on the platform, recorded as 250 variables, has a weight of 6% in the decision.
Types of Machine Learning Models Used in Credit Scoring
The common types of machine learning algorithms include supervised machine learning, unsupervised machine learning, and semi-supervised machine learning. Each of these sub-classes relies on different techniques (models) for training the machine to perform a particular task.
Below are examples of machine learning algorithms that are successfully deployed for credit scoring.
Logistic Regression
Logic regression is a statistical method for making binary predictions. For example, determining if a particular loan will default or not. By assessing, the available data the model determines the probability of a borrower’s default on a scale of 0 and 1, where 1 means a firm yes and 0 definitive no. Such models can not only make predictions but also help understand which factors can affect the probability.
For example, a group of researchers applied a logistic regression model to credit scoring data from a Portuguese financial institution. The model predicted the default rates correctly in 89.79% of the cases. It also showed that the risk of default increased with loan term and spread, but curiously decreased if the customer owned several credit cards.
Decision Trees
Decision Tree models can forecast or classify future observations based on a set of decision rules. Such algorithms split the available dataset into subsets, such as high-risk versus low-risk loans. Then, you can use this data to develop classification rules based on the most significant features within the data set. The result resembles a tree-like structure where each node represents a decision based on certain analytical criteria and each leaf node represents a final prediction.
Decision tree models offer a repeatable and explainable way of analyzing data, making it a popular technique for credit scoring. The World Bank endorses the use of decision trees, as well as regression, random forests, and gradient-boosting models for credit scoring.
Random Forests
Random forest model combines the outputs of several decision trees to deliver more accurate and comprehensive classifications. The model randomizes features when building each decision tree to create an uncorrelated forest of trees to provide a more accurate vote-based decision jointly. Each tree can analyze the problem using different factors, resulting in more reliable predictions.
Deloitte tested a random forest model for credit risk scoring and found that this approach offers better advantages in terms of accuracy, but has slightly lower interpretability and requires more computation time.
In particular, the random forest model better assigned the importance of different variables for predicting credit risks and it better handled missing data in the dataset, still being able to rightfully identify correlations between variables even when some records were missing or incomplete.
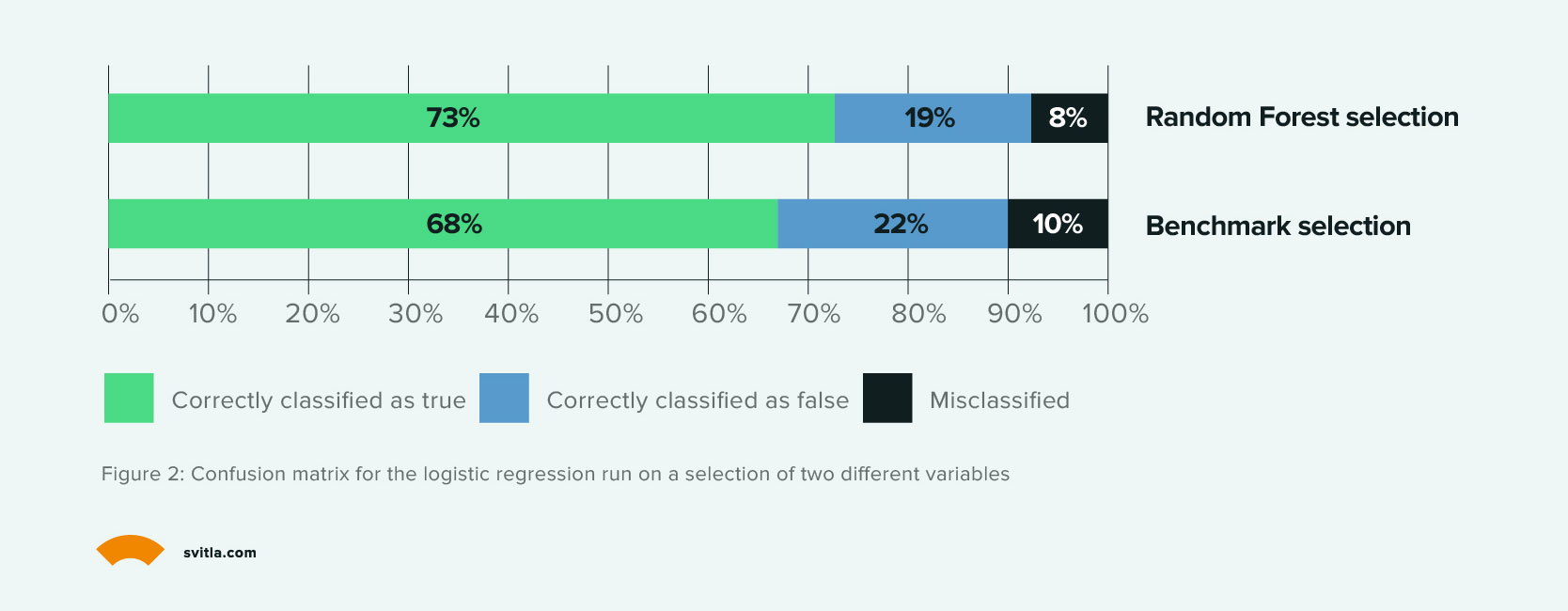
Source: Deloitte
Deep Neural Networks
A neural network model includes several interconnected nodes, called neurons, stacked in layers. The model processes incoming data at each layer, passing on new “knowledge” to the next one to make predictions.
Deep neural networks (DNNs) have several types of processing layers, with each optimizing and refining the output for accuracy.
Unlike the previous machine learning models, neural networks can also work with unstructured data such as text, video, audio, or images. Deep neural networks can automatically determine which features of the presented information are the most important for processing the incoming data (e.g., distinguishing between a genuine credit card statement and a fake one).
Deep neural networks help accomplish more complex tasks such as optical character recognition (OCR) or natural language processing (NLPs). Such algorithms can “read” texts from visuals or extract the sentiment from the provided text records.
Although not still widely deployed for credit scoring, neural networks have been successfully tested for processing credit data in image format and predicting the probability of late payments by a customer using behavioral factors.
Challenges of Using Machine Learning for Credit Scoring
When done right, machine learning can improve credit assessment speed, accuracy, and fairness. However, such models can also introduce new operational risks that must be managed.
Flawed Data
Machine learning models require ample, representative data sets for training. But as recent research found, flawed financial data may aggravate credit accessibility issues. Many of the ML models are trained on the available credit score datasets, yet such records don’t include information from credit-thin consumers, who often come from low-income and minority backgrounds. When trained on such data, the model would struggle to classify such borrowers in the future accurately.
On the pro side, researchers are countering this issue with alternative scoring techniques. For example, a DualFair algorithm evaluates each data point to determine the presence of the bias. If a female Black borrower were rejected for a loan, the algorithm would remove her race and gender to rerun the evaluation. If the same borrower is approved, DualFair will mark this data point as biased and remove it from the dataset.
Uncertain Regulations
Most financial regulations and policies were put in place before the proliferation of ML. At present, no clear guidelines exist for using machine learning models for credit scoring. Regulators emphasize that “AI,” “ML,” and “automated” credit models must still follow the principles of fair competition, consumer protection, and equal opportunity. Yet few elaborate their expectations further.
Uncertain regulatory status may deter some financial institutions from developing such solutions, while others might find themselves unsavory if the regulations change.
Data Security
ML models will need access to sensitive customer data to perform underwriting. Some global laws limit the type of data lenders can collect for underwriting. However, even with purposefully omitted or anonymized customer data, sophisticated models can still effectively identify consumers’ age, race, or gender — and use this data to draw biased decisions.
In addition, digitization of the lending activities calls for greater improvements in cybersecurity. The financial sector is already a prime target for hackers. With more data being exchanged, stored, and processed online, banks must ensure its topmost protection.
To Conclude
Machine learning has a strong potential to create a more accessible lending environment for consumers while helping banks maintain ultra-low NPL targets and high operating efficiencies.
Digital lenders worldwide have already proved the viability and scalability of ML-based assessments, while traditional financial institutions are looking for new ways to improve their credit scoring, for example, by using NLP to analyze corporate credit as Bank of America does.
Svitla's AI and Machine Learning team will help you explore the possibilities of machine learning in finance and confidently implement new solutions. Contact us, and we’ll get back to you promptly.



