

Hadoop and Spark - History of the Creation
The Hadoop project was initiated by Doug Cutting and Mike Cafarella in early 2005 to build a distributed computing infrastructure for a Java-based free software search engine, Nutch. Its basis was a publication of Google employees Jeff Dean and Sanjay Gemawat on the computing concept of MapReduce.
During 2005-2006 Hadoop was created by the two developers, Doug Cutting, and Mike Cafarella, working part-time on the project. In January 2006, Yahoo requested that Cutting lead a dedicated team to develop a distributed computing infrastructure, with Hadoop being designated a separate project at the same time. In February 2008, Yahoo launched a clustered search engine based on 10,000 processor cores operated by Hadoop in productive operation.
In January 2008, Hadoop became the top-level project of the Apache Software Foundation project. In April 2008, Hadoop beat the world record of performance for a standardized benchmark, sorting data (1 TB was processed for 309 seconds in a cluster of 910 nodes). Since then, Hadoop has begun to be widely used outside of Yahoo - the technology is used by Last.fm, Facebook, The New York Times, and there is an adaptation to launch Hadoop in the Amazon EC2 clouds. In September 2009, Cutting moved to California's Cloudera startup.
In April 2010, Google granted the Apache Software Foundation the right to use MapReduce technology three months after its defense at the US Patent Office, thereby depriving the organization of possible patent claims.
Since 2010, Hadoop has become a key technology of Big Data. It is widely used for mass-parallel data processing, along with r Cloudera, a series of technology startups that are fully aimed at the commercialization of Hadoop technology. During 2010, several sub-projects of Hadoop - Avro, HBase, Hive, Pig, Zookeeper - became and have remained Apache's top-level projects.
The Spark project was launched by Matei Zaharia AMPLab of Berkeley University in 2009, and its code became open in 2010 under the BSD license.
In 2013, the project was presented by Apache Software Foundation and changed its license to Apache 2.0. In February 2014, Spark became the top-level project in the Apache Software Foundation.
In November 2014, the Databricks company, founded by Matei Zaharia, used Spark to set a new world record for sorting large volumes of data.
Spark had over 1,000 project participants in 2015, making it one of the most active projects in the Apache Software Foundation and one of the most active projects for large open-source data.
To select the right technology concerning Spark vs Hadoop it is necessary to refer to the concept of distributed computation.
Distributed computing concept
Distributed computing (distributed data processing) - a way to solve large computational tasks using two or more computers that are networked.
Distributed computing is a special case of parallel computing; that is, the simultaneous solution of different parts of one computing task by several processors using one or more computers. It is necessary that the task to be solved was divided into subtasks that can be computed in parallel.
In this case, for distributed computing, it is necessary to take into account the possible difference in the computing resources that will be available for the calculation of various subtasks. However, not every task can be "parsed" and its solution accelerated with the help of distributed computing.
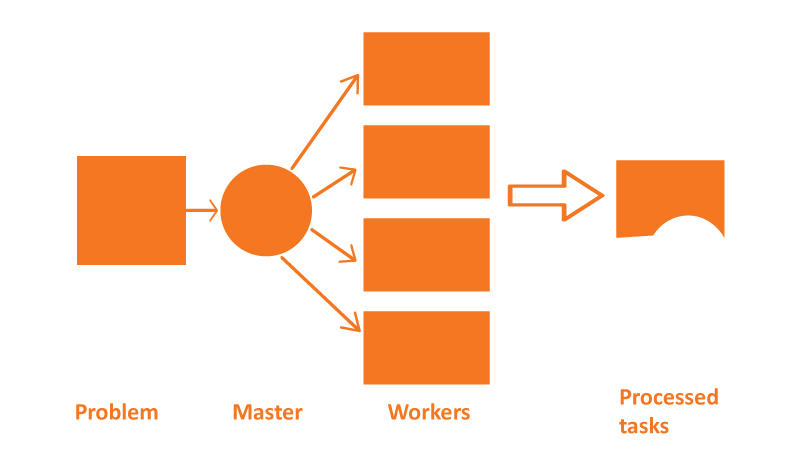
Fig. 1. Distributing computing concept.
Hadoop vs Spark - Overview and Comparison
Spark
Spark is an open-source cluster computing platform, similar to Hadoop framework, but with some useful features that make it an excellent tool for solving some kinds of tasks.
Namely, in addition to interactive queries, Spark supports disbursed data sets in memory, optimizing the solution of iterative tasks and implicit data parallelism and fault tolerance. It is designed to solve a huge range of workloads such as batch applications, iterative algorithms, interactive queries, and streaming.
Spark is implemented in the Scala language and used as an application development environment. Unlike Hadoop, Spark and Scala form tight integration where Scala can easily manipulate distributed data sets as local collective objects.
Although Spark is designed to solve iterative problems with distributed data, it actually complements Hadoop and can work together with the Hadoop file system. In addition, Spark introduced the concept of a sustainable common data set (resilient distributed datasets - RDD). RDD is a collection of immutable objects distributed over a set of nodes.
In Spark, applications are called drivers, and these drivers perform operations that are performed on a single node or in parallel on a set of nodes. Like Hadoop, Spark supports single-node and multi-node clusters.
Spark Core It is the kernel of Spark.
Spark SQL
It enables users to run SQL/HQL queries on the top of Spark.
Spark Streaming
Apache Spark Streaming allows building data analytics application with live streaming data.
Spark MLlib
It is the machine learning library for scaling application with high-performance algorithms.
Spark GraphX
Apache Spark GraphX is the graph computation engine.
SparkR
It is an R package that gives light-weight frontend to use Apache Spark from R.
Resilient Distributed Dataset RDD
Apache Spark has a key abstraction of Spark known as RDD or Resilient Distributed Dataset. RDD is the fundamental unit of data in Apache Spark. This unit represents a distributed collection of elements across cluster nodes. It is used to perform parallel operations. Spark RDDs are immutable but at the same time can generate new RDDs by transforming an existing RDD. Apache Spark RDDs support two types of operations.
| Type of operation | Meaning |
| Transformation | Creates a new RDD from the existing one. It passes the dataset to the function and returns new dataset. |
| Action |
Spark Action returns final result to driver program or writes it to the external data store. |
Please take a look at how Apache Spark describes distributed tasks in a compact and easy-to-read form (source).
Scala
val count = sc.parallelize(1 to NUM_SAMPLES).filter { _ =>
val x = math.random
val y = math.random
x*x + y*y < 1
}.count()
println(s"Pi is roughly ${4.0 * count / NUM_SAMPLES}")Code language: PHP (php)Python
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(xrange(0, NUM_SAMPLES)) \
.filter(inside).count()
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)Code language: PHP (php)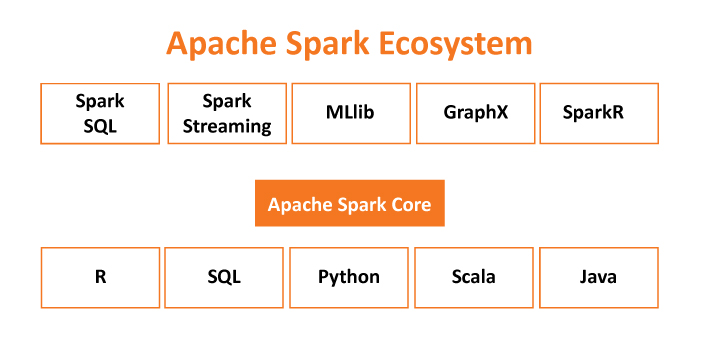
Fig. 2. Apache Spark ecosystem.
Hadoop
Hadoop MapReduce is a software framework for effortlessly writing applications which contain a huge number of records (multi-terabyte data-sets) in-parallel on giant clusters (thousands of nodes) in fault-tolerant mode. It is designed to process large amounts of data from file systems, and the high-performance Hadoop Distributed File System was created especially to read, process and store huge amounts of data on a cluster of a large number of computers.
A MapReduce job commonly splits the input data-set into detached chunks. These chunks are processed by mapping tasks in parallel. Typically the input and the output of the job are each saved in a file-system. The framework automatically works on scheduling tasks, monitoring and re-executing the failed tasks.
Usually, the compute nodes and the storage nodes are the same, i.e. the MapReduce framework and the HDFS are running on the same nodes. This configuration allows the framework to effectively schedule tasks between nodes.
The Hadoop ecosystem also consists of the following components:
- MapReduce (Data Processing)
- Yarn (Cluster Management)
- HDFS (Hadoop Distributed File System)
- Pig (Scripting)
- Hive (SQL Query)
- Mahout (Distributed Linear Algebra Framework)
- HBase (Columnar Store)
- Oozie (Work Flow Management)
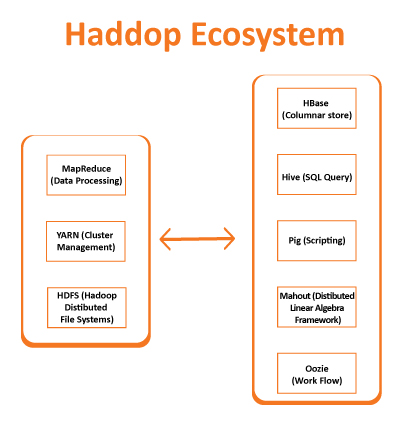
Fig. 3. Hadoop Ecosystem (main components).
A simple example of Hadoop looks like this. Please refer here for more information. (Source)
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Code language: JavaScript (javascript)As you can see by analyzing the source code the Spark vs Hadoop choice is obvious and Spark in this case looks more compact and easy to use.
Spark vs Hadoop conclusions
First of all, the choice between Spark vs Hadoop for distributed computing depends on the nature of the task. It cannot be said that some solution will be better or worse, without being tied to a specific task. A similar situation is seen when choosing between Apache Spark and Hadoop.
| Key features | Apache Spark | Hadoop MapReduce |
| Speed | About 100 times faster than Hadoop | Faster than non-distributed systems |
| Data model | Use in-memory model to transfer data between RDD | Use HDFS to read, process and store large amounts of information (always use persistent storage) |
| Created in | Scala | Java |
| Style of processing | Batch, real-time, iterative, interactive, graph | Batch |
| Caching | Store data in memory | Caching data is not supported |
Spark is great for:
- Iterative algorithms, processing of the streaming data
- Real-time analysis
- Machine Learning algorithms
- Large graph processing
Hadoop is great for:
- Analysis of large data collection
- Data analysis where time factor is not critical
- Step-by-step data processing of large datasets
- Works perfectly if you need to manage large amounts of stored data
In general, the choice between Spark vs Hadoop is obvious and is a consequence of the analysis of the nature of the tasks. The advantage of Spark is speed, but, on the other hand, Hadoop allows automatic saving for intermediate results of calculations. As Hadoop works with persistent storage in HDFS it is slow compared to Spark, but the saved intermediate results help to continue processing from any point.
Another advantage of Spark is simple coding in many programming languages. A Spark code is smaller and easier to read compared to Hadoop. Users can write code in many programming languages including R, Scala, Python, Java and use SQL.
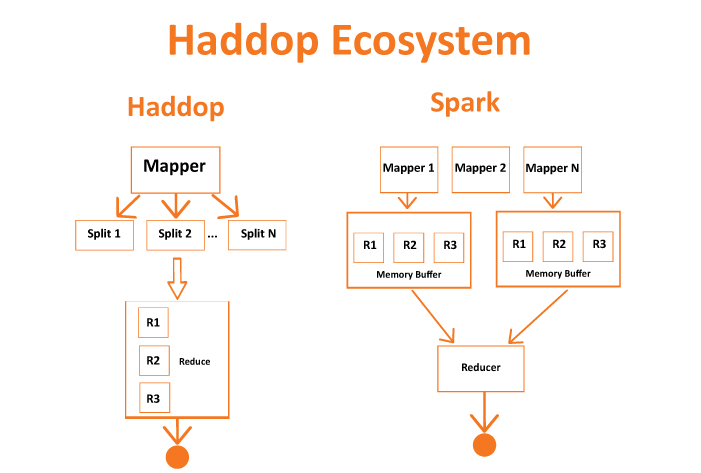
Fig. 4. Hadoop vs Spark computation flow.
Cloud Systems and Spark vs Hadoop Usage
Cloud-native Apache Hadoop & Apache Spark
Cloud Dataproc is a fast, easy-to-use, completely managed cloud service for running Apache Spark and Apache Hadoop clusters in a simpler, more affordable way. Cloud Dataproc additionally effortlessly integrates with other Google Cloud Platform (GCP) services. It provides an effective platform for data processing, analytics and learning:
Automated Cluster Management
- Resizable Clusters
- Integrated (Built-in integration with Cloud Storage, BigQuery, Bigtable, Stackdriver Logging, and Stackdriver Monitoring)
- Versioning (allows to switch between different versions of Apache Spark, Apache Hadoop, etc)
- Highly available
- Developer Tools (easy-to-use Web UI, the Cloud SDK, RESTful APIs, and SSH access)
- Initialization Actions
- Automatic or Manual Configuration
- Flexible Virtual Machines
Amazon EMR
Amazon EMR has built-in help for Apache Spark, which lets it quickly and easily create managed Apache Spark clusters through the AWS Management Console, AWS Command Line Interface or Amazon EMR API.
Also, extra Amazon EMR features are available, including fast connection to Amazon S3 using the EMR file system (EMRFS), integration with the Amazon EC2 spot instance store and the AWS Glue information catalog, and Auto Scaling to add or dispose of instances from the cluster.
It is possible additionally to use Apache Zeppelin to create interactive collaboration notebooks for information exploration through the use of Apache Spark and use deep knowledge of platforms, such as Apache MXNet, in Spark-based applications.
Difference between Hadoop and Spark - Final words
Apache Spark is a real-time data analysis system that basically performs computing in memory in a distributed environment. It offers great processing speed, which makes it very appealing for analyzing large amounts of data. Spark can work as a stand-alone tool or be associated with Hadoop YARN. Spark is a great in-memory distributed computing engine.
Spark is an interesting addition to the growing family of large data analysis platforms. It is an effective and convenient platform (thanks to simple and clear scripts in Scala, Python) for processing distributed tasks.
Hadoop is based on the HDFS distributed system and uses MapReduce computational paradigm where an application is divided into a large number of identical simple tasks, then each of these tasks is executed on a node in the cluster and its result is reduced to the final output. In this case, Hadoop is a great solution for processing large data sets on a cluster of computers. Hadoop, first of all, is a framework for distributed storage and works with distributed processing YARN.
One of the biggest users and developers of Hadoop is Yahoo!, which actively uses this system in its search clusters (Hadoop-cluster of Yahoo, consisting of 40 thousand nodes). The Hadoop cluster is used by Facebook to handle one of the largest databases, which holds about 30 petabytes of information. Hadoop is also at the core of the Oracle Big Data platform and is actively adapted by Microsoft to work with the SQL Server database, Windows Server. Nevertheless, it is believed that the horizontal scalability in Hadoop systems is limited, for up to version 2.0, the maximum possible was estimated at 4 thousand. nodes using 10 MapReduce jobs per node.
Both systems, Spark and Hadoop, are the right and effective tools for high-power distributed computing. This allows you to choose between tools you need to achieve the best results for your particular task, both in a cluster in your data center and in cloud systems.



