
Summary: Multimodal AI systems, which process text, images, audio, and video together rather than one input type at a time, are reshaping how industries make decisions from multi-format data. This article explores what multimodal AI is, how it works, which industries benefit the most, how the leading models compare, and what multimodal AI breakthroughs mean for enterprises in 2026.
For most of AI's commercial history, models have done one thing at a time, like processing text, analyzing images, or handling audio. If an organization needed to work with more than one type of data, it had to stitch models together with custom pipelines and hope the integration held up.
Instead of separate models connected by engineering tape, multimodal AI processes text, images, audio, and video together, reasoning across all of them simultaneously. The leading players in the field include:
- Google's Gemini processes text, images, audio, and video natively with a million-token context window, scoring 78.2% on the Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark (MMMU).
- Claude combines image understanding with tool use and computer interaction.
- OpenAI's GPT-4o responds to voice while processing images and text simultaneously.
- Grok integrates real-time data from the X platform with vision capabilities.
Organizations are now applying the technology to problems where the data was always multi-modal, but the tools could only see one format at a time.
In this article, we cover how multimodal AI works. We also explore the industries that benefit the most, how the major models compare, recent breakthroughs, and the challenges that come with training systems on data that span text, images, audio, and video simultaneously.
How does multimodal AI work?
Most production multimodal AI systems process each input type through its own encoder before combining them into a shared representation the model reasons over.
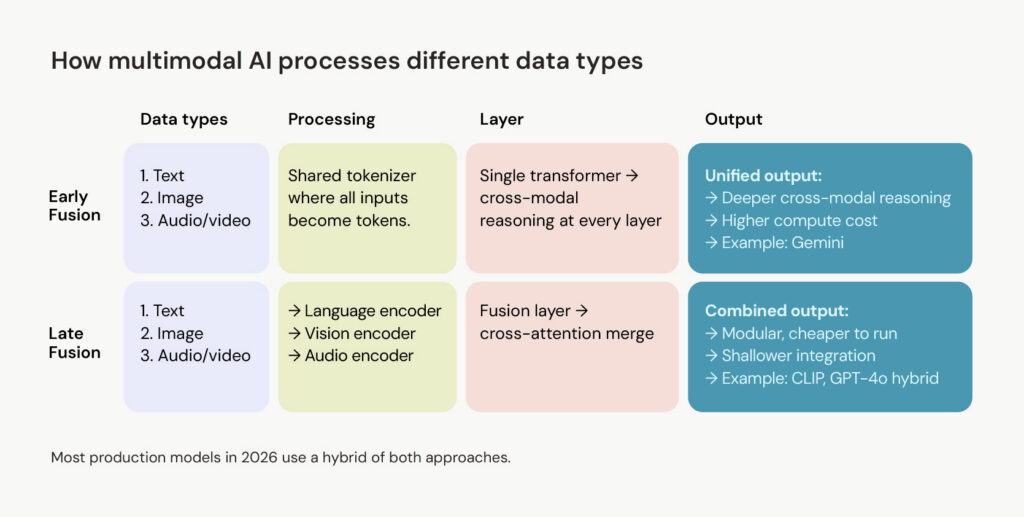
The difference between models comes down to how early that combination happens. Gemini merges all modalities from the first layer, which produces deeper cross-modal reasoning but costs more to run. GPT-4o and Claude process each type separately before merging, which is more modular and cheaper, but slightly shallower on tasks that require tight reasoning across formats.
Most models in 2026 use something in between. For production decisions, it’s valuable to evaluate whether the model handles your specific combination of inputs natively or stitches them together through separate components.
Which industries benefit most from multimodal AI?
Organizations are applying multimodal AI in areas where decisions depend on combining multiple data types. In these scenarios, humans have always been the integration layer. Now, multimodal AI replaces manual analysis with systems that process all inputs together.
A multimodal AI agent can read a document, analyze an image, listen to a call recording, and then do something with what it found: file a report, flag an anomaly, update a record, or escalate to a human. That combination of perception and action is what makes agents different from the AI tools most organizations use today.
Healthcare
Clinicians have always integrated multiple data streams (imaging, clinical notes, lab results, patient history) to make diagnoses. Today, AI can do the same.
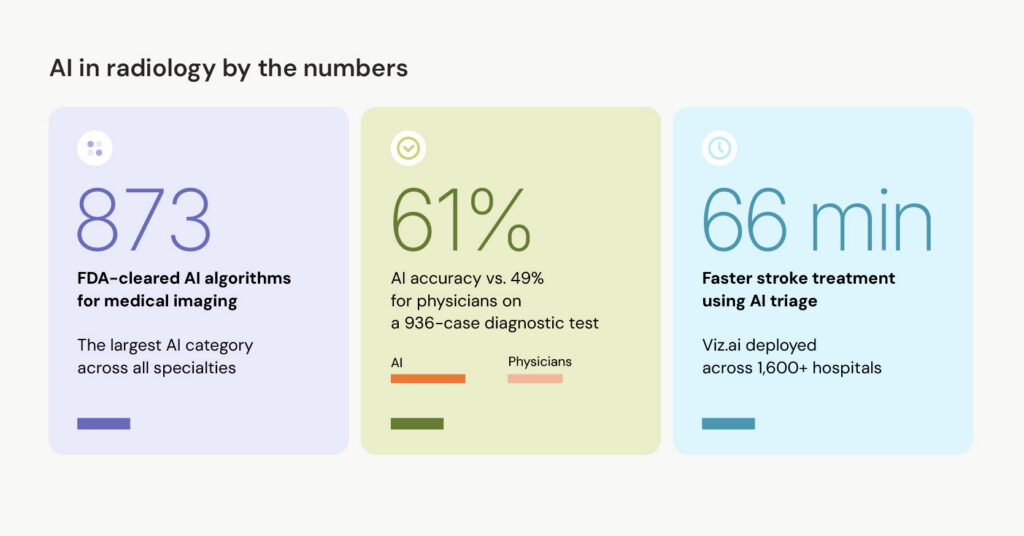
Multimodal GPT-4V models achieved 61% accuracy on a 936-case diagnostic challenge, outscoring physician who averaged 49%. That's a striking result, but there’s context worth noting: detecting pathology from radiologic images alone remains unreliable with current models.
The accuracy improves when the model combines the image with clinical context, lab values, and patient history. This is exactly the case for multimodal over single-mode models: the image itself isn't enough for a diagnosis. Neither is the text. Together, they're closer to how a clinician thinks.
Multimodal AI systems combine images with EHR data, genomics, and wearable sensor data to predict outcomes like cancer recurrence or the progression of diabetes. In drug discovery, multimodal AI systems integrate molecular structures, chemical properties, and biomedical literature to identify new drug candidates. KMC Manipal Hospital in India used AI-enabled imaging workflows to serve 20 to 30 additional patients daily while maintaining diagnostic accuracy.
48% of European radiologists are using AI tools, but only 2% of US practices have adopted them. Adoption is still slow due to two factors: regulatory requirements (the EU AI Act classifies most radiology AI as "high-risk") and legal liability (63% of radiologists worry about who holds liability when AI is involved).

Manufacturing
A quality inspection system that combines camera footage with sound analysis and vibration sensor data catches defects that look fine but sound wrong or vibrate in patterns that signal an internal flaw. That's a superior level of inspection accuracy.
On assembly lines, multimodal systems detect scratches, dents, and misalignments using computer vision while simultaneously analyzing audio and readings from temperature, pressure, and humidity sensors.
These systems run continuously without breaks, maintain inspection quality, and generate inspection data that feeds back into the model, making it more accurate over time.
Financial services
In financial services, multimodal AI is used mainly for fraud detection and identity verification. Instead of analyzing transactions alone, multimodal systems combine behavioral biometrics, device fingerprints, voice authentication, and facial recognition. This layered approach reduces false positives and improves the detection of more complex fraud patterns.
Another use case is insurance underwriting. Models assess claims by combining documents (photos, reports) with satellite imagery, weather data, and historical data.
Models that use biometrics, voice data, and behavioral patterns for fraud detection must comply with privacy regulations (GDPR, CCPA, state-level biometric laws) that add engineering and legal costs.
Retail and e-commerce
Retail is a clear use case for multimodal AI because the data has always been multimodal in nature. A customer’s purchase signal includes what they browsed, what they clicked, what they returned, and what they searched for.
AI personalization drives a 5 to 15% revenue lift for most retailers, with top performers reaching 25%. Product recommendations powered by AI drive 25 to 35% of total e-commerce revenue. On the traffic side, AI-referred shoppers convert 31% higher and spend 45% more time on retailer sites than those arriving through traditional channels.
On the user experience side, AI-powered stylists combine browser history, product catalogs, and pricing to deliver recommendations that match visual preferences and past purchases. On the operations side, multimodal AI analyzes product reviews, in-store video feeds, and sales data for inventory and merchandising decisions.
In customer service, sales, and internal support, an agent can handle the full intake cycle. A customer submits a photo of a damaged product with a written complaint. The agent reads the complaint, assesses the damage, checks order history, and issues a resolution...all without a human in the loop.
Automotive
The automotive industry has been building multimodal systems for some time now because autonomous driving is inherently multimodal. A self-driving vehicle fuses camera images, radar signals, GPS data, and more to understand its environment and cover each sensor’s blind spots.
Beyond driving, automotive manufacturers apply multimodal inspection to quality control on the production line, combining visual inspection with acoustic testing (tapping parts and analyzing the sound signature for internal defects) and dimensional measurement sensors.
The common thread across industries is that agents handle the part of every workflow that involves gathering information from multiple sources, making judgment calls, and routing the work to relevant areas.
Where agents still fall short
The reliability question is the biggest open issue. Hallucination rates across major models surged from 18% in 2024 to 35% in 2025. For a model that only answers questions, a hallucination is an incorrect response that a human can catch and discard.
For an agent that acts, a hallucination can trigger a wrong decision that spreads through systems before anyone notices. A customer service agent that misreads a screenshot and issues an incorrect refund creates a real financial consequence. A clinical agent that hallucinates a lab result could feed incorrect data into a treatment decision with serious consequences for the patient.
This is why production multimodal agents operate with strict guardrails:
- Confidence thresholds determine when the agent acts independently versus when it escalates to a human.
- Action boundaries define what the agent can and cannot do.
- Audit logging records every perception, reasoning step, and action for post-hoc review.
What are the major multimodal AI models, and how do they compare?
The multimodal AI market in 2026 doesn't have a single winner. Each major model has carved out a different strength, and the best choice depends on what the use case requires. Here is how each model compares across benchmarks, capabilities, and tradeoffs.
| Model | Modalities | Best for | Weaknesses | API pricing (input / output) |
| Gemini 2.5 Pro / 3.1 Pro | Text, images, audio, video | Video understanding, cross-modal reasoning, Google Workspace integration, long context (1M tokens); Gemini 3.1 Pro is the most advanced Gemini model, scoring 77.1% on ARC-AGI-2 and optimized for complex multi-step agentic workflows. | Verbose code output; conservative responses; weaker outside Google ecosystem; Gemini 3.0 can show "AI laziness" on complex prompts and loses contextual focus at long context lengths compared to 2.5 Pro. | Gemini 2.5 Pro: $1.25–$2.50 / $10–$15 per 1M tokens; Gemini 3 Pro Preview: $2.00 / $12.00 per 1M tokens |
| GPT-5 / GPT-5.5 | Text, images, audio | Voice interactions via GPT-Realtime-2 (sub-300ms), complex reasoning, coding; GPT-5.5 has a 1M+ token context window with text and image inputs for large-scale reasoning and multimodal workflows | No native video generation; GPT-5.5 doubled per-token prices over GPT-5.4 with the April 2026 release; highest cost tier among frontier models | GPT-5.5: $5 / $30 per 1M tokens; GPT-5.4: $2.50 / $15 per 1M tokens |
| Grok 4.3 / 4.20 | Text, images | Real-time social data (X platform), advanced reasoning, lowest cost among frontier models; Grok 4.3 supports a 1M token context window with no output token limit, suited for long-document analysis and multi-step agentic tasks | No native audio or video generation; lighter guardrails raise enterprise governance concerns; shorter enterprise track record | Grok 4.3: $1.25 / $2.50 per 1M tokens; Grok 4 Fast / 4.1 Fast: $0.20 / $0.50 per 1M tokens |
| Claude Sonnet 4.6 / Opus 4.7 | Text, images, documents | Long-form output (1M token context), legal and report writing, agentic computer use, safety; Sonnet 4.6 hit 94% accuracy on insurance computer use benchmarks, the highest of any model tested | No native audio or video; no image generation, audio processing, or video capabilities | Sonnet 4.6: $3 / $15 · Opus 4.7: $5 / $25 per 1M tokens |
Gemini (Google DeepMind)
Gemini stands out for the range of inputs it can handle natively. It processes text, images, audio, and video within a single architecture. It supports a million-token context window, which means it can ingest an entire book, an hour of video, or thousands of pages of documents and reason across all of them in a single session.
Gemini AI multimodal capabilities show the greatest results in video understanding and cross-modal reasoning. It can watch a video and answer questions about what happened in specific frames while referencing audio from a different timestamp. It can read a chart in a PDF, interpret the visual layout, extract the numbers, and explain the trend in the same interaction.
The integration with Google's ecosystem is a two-sided coin. Gemini works natively with Gmail, Drive, Docs, Maps, and YouTube. For organizations already on Google Workspace, this significantly simplifies the adoption process.
For those in Microsoft or mixed environments, that tight integration is less of an advantage. Gemini Enterprise, launched in late 2025 at $30 per user per month, bundles access to all Google AI tools. On the API side, Gemini 2.5 Pro costs $1.25 per million input tokens and $10.00 per million output tokens, making it one of the more cost-competitive flagship models.
Where Gemini falls short is code quality. It gets the job done but less elegantly than other tools like ChatGPT or Claude. For development teams maintaining large codebases, that verbosity makes things more complex over time. And while its knowledge base is fresh (cutoff around January 2025, supplemented by live Google Search), it has a reputation for overly conservative responses, a side effect of aggressive safety filtering.
GPT-4o and GPT-5 (OpenAI)
In enterprise settings, OpenAI's models are the most widely used multimodal systems. GPT-4o was trained end-to-end on text, audio, and images, allowing it to process voice with a response time of approximately 232 milliseconds, fast enough to feel like a natural conversation. It recognizes tone, emotion, and background noise, making it the strongest model for voice-based interactions.
GPT-5.5, introduced in mid-2026, represented a significant leap across coding, math, writing, and visual perception. The model also introduced selectable personalities: Cynic, Robot, Listener, Nerd — giving users control over tone and style.
By early 2026, GPT-5.5 matched its predecessor's per-token latency while performing at a higher level of intelligence, and used fewer tokens to complete the same tasks. It also reduced hallucinations in sensitive domains like law, medicine, and finance, and gained the ability to reference past conversations, files, and Gmail to give more personalized answers.
The Canvas editing environment gives users a collaborative workspace for text and code. On the API side, GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens, placing it at the higher end of pricing among frontier models.
OpenAI's models offer superior cross-platform flexibility, working well outside any single ecosystem, connecting to third-party tools through plugins and integrations. For development teams, ChatGPT offers a smoother coding experience than Gemini, with stronger performance on SWE-bench coding benchmarks (74.9%). The main tradeoff is that OpenAI's models currently cannot generate video (Sora was discontinued in April 2026). Also, their browsing capabilities are less seamless than Gemini's native Google Search integration.
Grok (xAI)
Grok stands out for two things no other major model offers: real-time social data and an unusually direct conversational style. Built by xAI, Grok is integrated with the X platform, giving it access to live social media data that other models can't see. For use cases involving social listening, trend monitoring, or real-time public sentiment, that integration is a genuine advantage.
The Grok AI multimodal capabilities include vision (image understanding) and strong reasoning. Grok 4 achieved the highest score on Humanity's Last Exam, a benchmark spanning mathematics, physics, chemistry, and engineering.
It scored 1586 on EQ-Bench3, the highest result among current models on this conversational quality benchmark. And the pricing is aggressive: Grok API costs just $0.20 per million input tokens and $0.50 per million output tokens, making it the cheapest frontier model by a wide margin.
Compared to Gemini and GPT-4o, Grok’s multimodal capabilities are narrower as it lacks native audio and video processing.
Its lighter content guardrails produce more direct, uncensored responses, which appeal to some users but raise governance concerns for enterprise deployment. And the X platform integration that makes it strong for social data also ties its real-time capabilities to a single source.
Claude (Anthropic)
Claude's multimodal capabilities are more targeted than Gemini's or GPT-4o's. It processes images, documents, and text. It also supports tool use, calling external systems and APIs as part of a workflow.
What distinguishes it is the quality of its reasoning and the length of its output. Claude can produce up to 128K tokens in a single response, making it the clear leader for long-form document generation, legal analysis, and comprehensive report writing.
At the same time, Claude powers Cursor, Windsurf, and Claude Code, three of the most widely used AI coding assistants. It offers a computer use feature (controlling a desktop, clicking buttons, filling forms), extending what the model can do beyond text-in, text-out interactions. Claude is consistently rated among the top models for output reliability and built-in safeguards against harmful content.
The pricing reflects quality positioning. Claude Opus 4.6 costs $15 per million input tokens and $75 per million outputs, making it the most expensive among frontier models. Claude Sonnet 4.6 at $3 input and $15 output offers a more accessible option that retains most of Opus's capabilities.
Choosing the right multimodal AI for your use case
In 2026, there’s not a single model leading every category. And that’s by design. Each major player has optimized for a different combination of modalities, pricing, and use cases. The practical breakdown is:
- Broadest multimodal range (text, images, audio, video): Gemini
- Best voice interaction and cross-platform flexibility: GPT-4o/GPT-5
- Cheapest API with real-time social data: Grok
- Strongest writing, coding, and document analysis: Claude
For enterprise deployments, the model choice matters more than the data systems around it. Teams deploying AI agents for customer service, sales, and internal support consistently see 40 to 60% better automation rates. The orchestration layer, data integration, governance, and measurement determine ROI more than the choice of a model.
CTA Banner #2
What are some recent multimodal AI breakthroughs?
The past six months have seen a more meaningful multimodal progress than the previous two years combined. Google, Anthropic, OpenAI, and xAI each shipped major model updates. And for once, the benchmark improvements pointed to things that change what organizations can build. Four developments stand out as consequential rather than incremental.
The million-token context became real
For years, "long context" meant processing a few thousand words at a time. Gemini 3 Pro shipped with a one-million-token context window that works across text, code, images, video, audio, and PDFs simultaneously. That's roughly an entire novel, an hour of video, or thousands of pages of documentation processed together, in one pass.
Multi-step reasoning crossed a threshold
Gemini 3 achieved a historic 1501 Elo score on LMArena, the first model to surpass the 1500-point threshold. The model could execute 10 to 15-step reasoning chains without losing coherence, a task where previous models degraded after 5 or 6 steps.
Google's Deep Think mode pushed reasoning scores even higher on complex scientific and mathematical problems. Grok 4 matched this using a multi-agent architecture where multiple reasoning agents explored proof strategies simultaneously. It became the first AI to exceed 60% on USAMO mathematical problems.
Real-time multimodal interaction became fluid
GPT-Realtime-2 is OpenAI's first voice model with GPT-5-class reasoning, and it pushes real-time conversation further than its predecessors. The model delivers natural, bidirectional voice conversations with sub-300ms latency, with no separate speech-to-text or text-to-speech pipeline required.
The latency threshold for feeling "natural" in conversation is roughly 300 milliseconds. Dropping below it changes the interaction from something people tolerate to something they prefer.
Developers can now tune reasoning effort with low set as the default to keep latency tight for everyday back-and-forth, while harder requests can draw on deeper deliberation.
Gemini followed a different path to real-time interaction by integrating live search. It can analyze an image you just captured, search for context about what's in it, and respond with information that combines what it sees with what it found, all in one interaction.
Video understanding moved from demo to product
Gemini 3's multimodal processing handles continuous video as a true input type. It can track objects across frames, understand temporal relationships (what happened before and after a specific moment), and correlate visual events with audio or text overlays.
What does multimodal annotation involve?
Multimodal AI depends on labeled data. That means aligning text, images, and audio so the model understands how they relate. This process is called multimodal annotation.
The global AI annotation market reached $1.96 billion in 2025 and is projected to grow to $17.37 billion by 2034, driven by the data demands of foundation model training. Scale AI, a leading data annotation company, reported revenue of $2 billion in 2025, reflecting how much leading AI labs are willing to pay for quality training data. Meta invested $14.3 billion for a 49% stake in Scale AI in mid-2025, confirming that data annotation has become strategic infrastructure rather than a commodity service.
The leading AI multimodal annotation providers fall into three categories, each suited to different organizational needs.
- Platform-first providers like Labelbox and Encord give technical teams the tools to manage annotation workflows in-house. They offer customizable interfaces, model-assisted labeling, and SDK integrations. Labelbox supports images, video, text, geospatial data, audio, and medical imagery with native automation features. Encord specializes in regulated industries with HIPAA and SOC 2 compliance built in.
- Hybrid providers like Scale AI and SuperAnnotate combine platform tooling with managed workforces, meaning they provide and manage teams of annotators who label and review data. SuperAnnotate is known for combining an advanced platform with a vetted annotation workforce. Scale AI remains the volume leader for massive projects with top-tier tech companies, though Meta's majority investment has raised vendor concerns.
- Workforce-first providers like iMerit, Appen, and Sama focus on managed services with domain-trained annotators. iMerit specializes in complex edge-case scenarios across medical AI, autonomous vehicles, and geospatial analysis. Appen offers multilingual coverage across 200+ languages. These providers are strongest when the annotation task requires specialized domain knowledge that can't be automated.
AI pre-labeling now handles 60 to 70% of initial annotation volume, but human experts remain essential for the remaining 30 to 40% that requires domain judgment, cross-modal reasoning, and quality assurance. This hybrid approach is faster and cheaper, but if the AI pre-labeling contains systematic errors, human reviewers may anchor to those errors rather than catching them.
Multimodal AI is closing capability gaps
The industries getting the most from multimodal AI (healthcare, financial services, manufacturing) are using it because the challenges they’ve always dealt with involve multiple data formats simultaneously.
The models are now catching up with the challenges. The organizations capturing returns were disciplined about choosing use cases with measurable baselines, building annotation pipelines for cross-modal quality, and deploying with security guardrails.
If you're building multimodal AI applications and need engineering teams with experience across computer vision, NLP, and multi-format data integration, Svitla's machine learning team helps organizations move from multimodal experiments to production systems.


![[Blog cover] Agentic AI vs traditonal automation](https://svitla.com/wp-content/uploads/2025/09/Blog-cover-Agentic-AI-vs-traditonal-automation-560x310.jpg)