

Part 1
Hello, everyone! My name is Oleksii; I'm a Machine Learning Engineer at Svitla Systems. Recently, the topic of artificial intelligence, its algorithms, and capabilities, especially in the field of GenAI, has become very relevant. Large Language Models (LLM) algorithms such as ChatGPT and LLAMA, as well as image generation models such as Mid Journey and DALL-E, have attracted a lot of attention to this area, which has prompted the creation of many new models, ideas, and startups. However, regardless of the novelty of the inventions, they are still based on basic concepts and details that will remain relevant for decades. This article will discuss one of these concepts, namely convolutional neural networks.
Introduction
Convolutional Neural Networks (CNN) are neural networks used for image processing. CNNs are used in computer vision tasks, such as image generation and classification, object and pose recognition, etc. These tasks were previously attempted to be solved using classical neural networks, such as Multilayer Perceptron (MLP), and various heuristic methods.
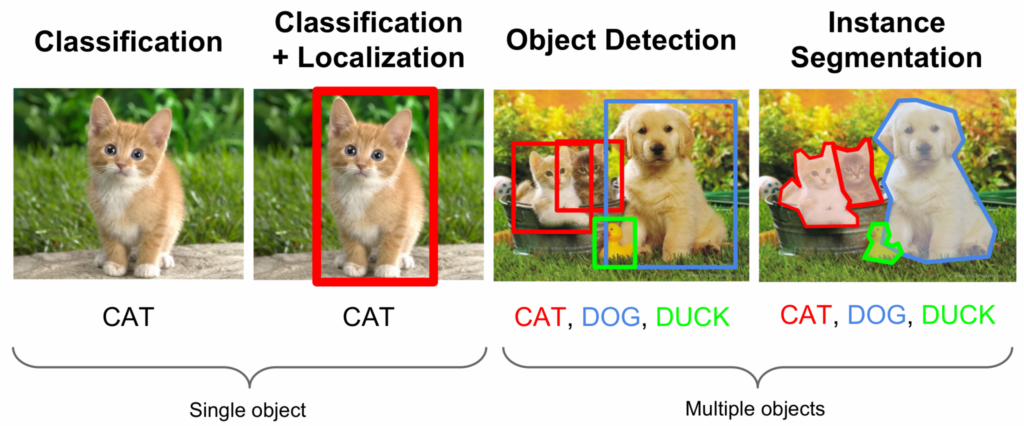
The image shows the difference between different tasks in computer vision, both for single and multiple objects.
Source: AIM
As for heuristic methods, the SIFT (Scale-Invariant Feature Transform) and SURF (Speeded Up Robust Features) algorithms are worth mentioning. They have been widely used to detect and describe local image features, such as lines, line edges, object recognition, and keypoint detection. These algorithms detect features different from the surrounding environment and help recognize objects regardless of scale, orientation, and lighting. However, these methods are limited, especially when dealing with more complex images and pattern recognition tasks. This led to the search for new approaches, including developing convolutional neural networks.
Moreover, CNNs are used to process two-dimensional and one-dimensional or even three-dimensional signals. For example, microphone signals are one-dimensional images that convolutional neural networks can use to recognize text. An example of such a model is the Jasper model from Nvidia. Three-dimensional images are videos where time becomes the third dimension:
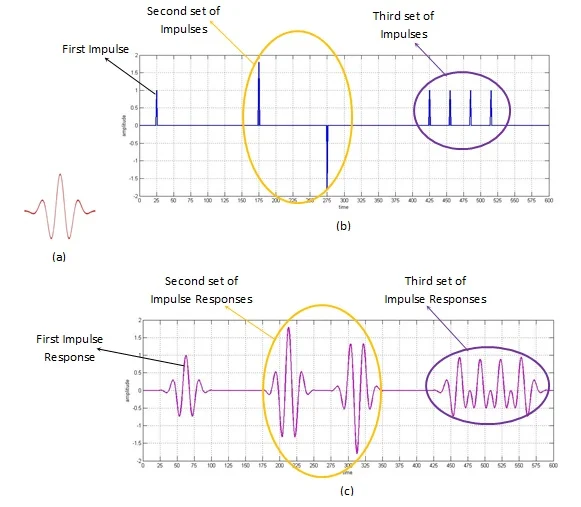
An example of the convolution of a one-dimensional and three-dimensional signal.
Sources: All About Circuits, Math Works
To better understand CNN, let's first dive into the world of classical image processing algorithms. We will focus on image filtering, one of the key aspects of image processing.
We've all used filters in phone editors or apps like Instagram. Filters highlight or hide specific characteristics of an image. For example, a filter can help emphasize the outlines of objects or make an image more blurry.

An example of how Canny filters work to highlight contours and a Gaussian filter to blur an image.
In the next section, I will explain how they work and their role in CNN. The only thing you need to understand for now is that convolutional neural networks, which will be discussed later, are based on similar filters (usually not just one, but a set of different filters). When applied one after another to an image, they allow you to obtain various features, such as vertical lines, horizontal lines, various curves, etc.

An example of how different filters in convolutional neural networks look to obtain visual features or image components.
Source: Medium
Motivation of CNN Development and History of Its Origin
Convolutional Neural Networks in the Brain
Artificial neurons, proposed in 1943 by scientists Warren McCulloch and Walter Pitts, were inspired by the structure and functionality of natural neurons. They became the basis for artificial neural networks that could perform simple classification tasks, such as identifying geometric shapes. Later, with the advent of more sophisticated algorithms, such as convolutional neural networks, artificial neurons were used to solve more complex problems, such as pattern recognition and image generation.
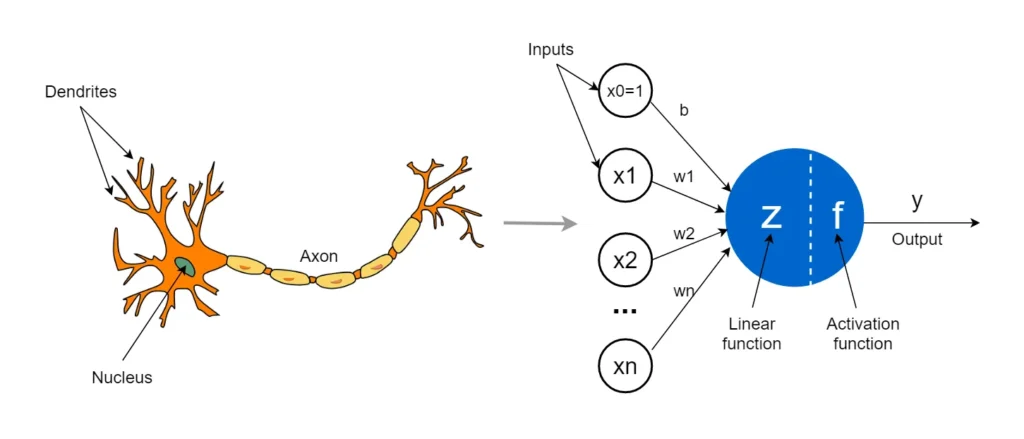
An artificial neuron model based on the morphology of a real neuron.
Source: Medium
The research that became the basis for convolutional neural networks was the work of Gubel and Wiesel in the 1950s and 1960s. This work identified two basic types of visual cells in the cat's cortex: simple and complex. They also proposed a model of these cells for image pattern recognition tasks. These discoveries became the basis for the creation of convolutional neural networks.
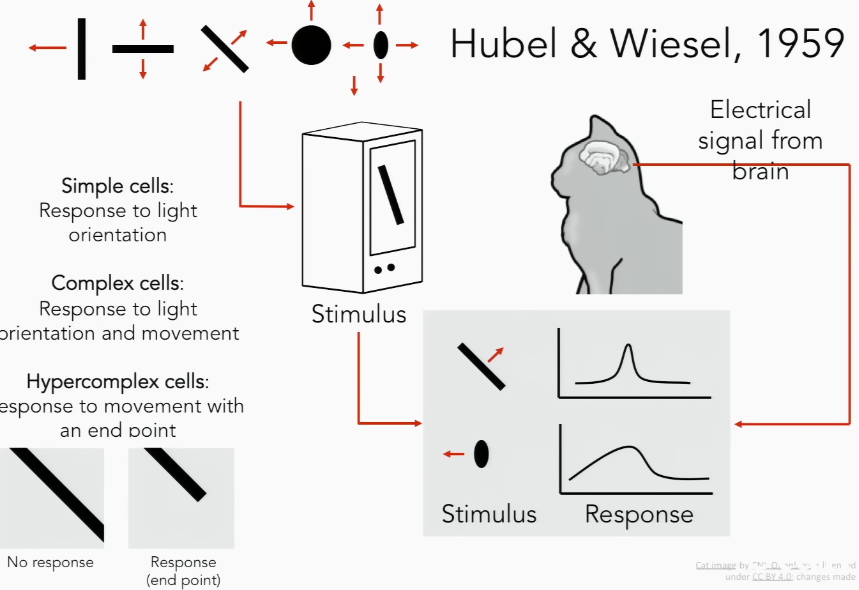
This image shows an experiment where a cat sees different images or stimuli. These stimuli are perceived by simple cells, and due to the orientation of the light, the cells capture a small region of the image. The captured image for complex cells is clearer due to the selection (maximization) of the edges of the image. Complex cells perceive not only the orientation but also the motion of the stimulus, and they transmit information about the position of the stimulus in the image. Hypercomplex cells, in turn, receive information about the position of the stimulus and its movement to some endpoint.
Source: Medium
The Neocognitron paper, first presented by Kunihiko Fukushima in 1980, was inspired by the work of Gubel and Wiesel. This publication introduced two basic types of layers in convolutional neural networks: the convolutional layer and the shrinking layer. These two layers reflect the simple and complex cells that Gubel and Wiesel discovered.
In particular, the convolutional layer includes neurons whose receptive fields cover the area of the previous layer, and the downsizing layer contains neurons whose receptive fields cover the areas of previous convolutional layers. In other words, the first layer generates features obtained by the filters we discussed above, and the second layer reduces the size of these “filtered” images. Thus, the above works of Gubel and Wiesel provided a theoretical basis for creating the architecture of convolutional neural networks.
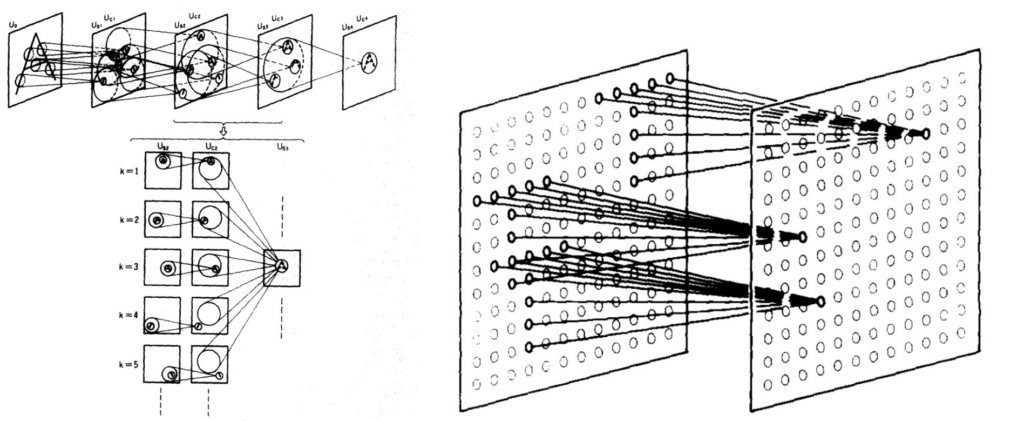
As you can see, pattern recognition is first performed by simpler cells by selecting image edges. With each new layer of neurons, the image becomes more complete and smaller, but with the correct position of the image and its elements.
Source: Neocognitron: A Hierarchical Neural Network Capable of Visual Pattern Recognition
Convolutional Operation
Why do convolutional neural networks have this name and not "neocognitive" networks as described by Fukushima? The answer is that the described edge detection process, from smaller local image features to more general ones, is mathematically described by an operation called convolution. It looks like this:
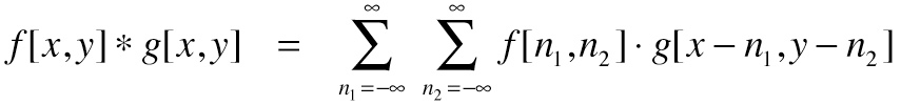
The convolution operation in two-dimensional space.
For those of you who are despairing about the formula above, don't worry. There is a relatively simple visual explanation below, and those interested in the mathematical details will find them in the next article.
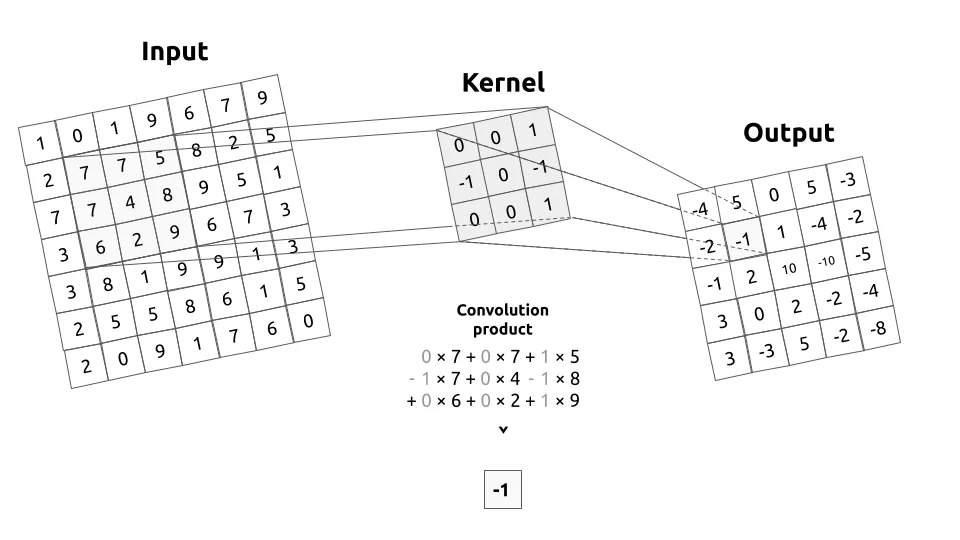
An example of a convolution operation where a filter is applied to the input image (Input). This means their values are multiplied and added to form new values for the next image (Output).
Source: Medium
In the example above, Input is any image. For simplicity, we'll assume it is black and white. The Kernel is a filter or kernel whose values are multiplied with the same 3×3 part of the Input image (Input), and this product is done for each part on each row and column. After the multiplication, the numbers are added together, and their sum forms the new image we see in the Output. Below is an animated visualization of how this process works for the entire image.
Source: Medium
Pulling Operation in Convolutional Neural Networks
We have considered only the first part of convolutional neural networks. The second part is the maximization function for a certain part of the image. The previous layer obtained features by filtering a specific part of the input image. The next layer processes the filtered image parts. This is done as follows: a certain area of the previous result is selected, and its maximum is found, which will be the output of the current layer. We do this for each section. The operation itself looks like this:
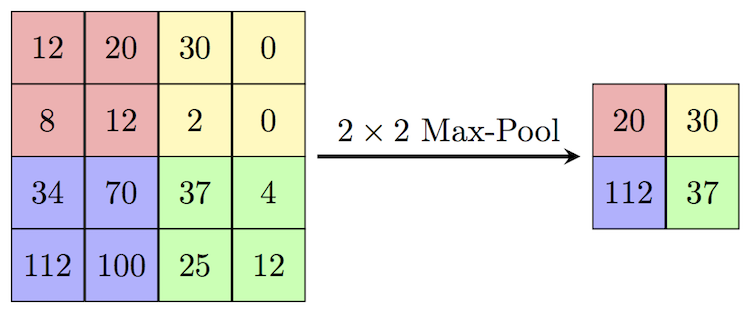
In this image, a 2x2 filter with a step of two performs the pooling operation. As you can see, the largest value is selected as the result of the pooling filter for each area processed.
Source: Papers With Code
This is a description of a single layer of a convolutional neural network: the first step is to convolve the image by applying a filter to it, and the second step is to maximize the areas on the resulting output.
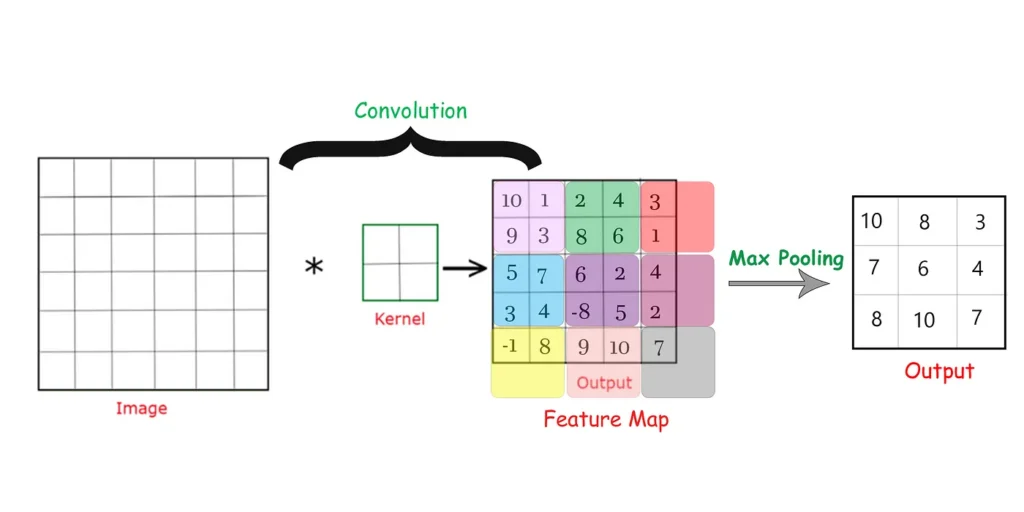
An example of how the convolutional neural network layer is organized. First, the Kernel filter convolved the Image, resulting in a new Feature Map image. After the convolution operation, the Max Pooling operation is applied to the Feature Map image, where the maximum value for each color area is selected, which is the result of the convolutional layer, i.e. Output.
Source: Medium
If the outputs from one layer of such a network are transferred to the input of another, we will get more complex patterns. And layer by layer, very simple lines and dots will turn into full-fledged prototypes of objects a person sees.

Examples of how convolutional neural networks see different objects during training. Images from simple cells are shown below, and complex and hypercomplex cells above.
Source: Medium
Types of CNNs
Convolutional neural networks are divided into 1D, 2D, and 3D by the type of dimension, and they can be divided into the following according to the type of tasks they solve:
1D CNN
Signal processing: 1D CNNs are often used to process time series or audio signals where important events or changes in the signal need to be detected.
2D CNN
- Image classification: 2D CNNs are the standard choice for image classification tasks. They can detect key features in an image and use them to determine its class.
- Pattern recognition: CNNs are used to recognize specific objects in images, from faces to cars.
- Image segmentation: CNNs can determine which segment each pixel in an image belongs to, allowing specific objects and areas to be highlighted.
3D CNN
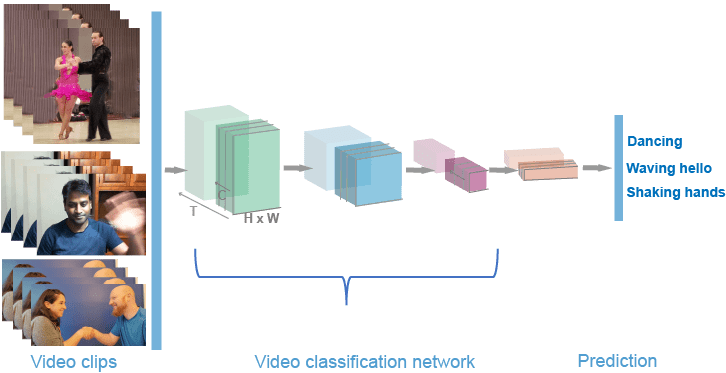
Video classification: 3D CNNs analyze video data and can account for both spatial and temporal information.
Let's talk about each type in more detail:
One-dimensional Convolutional Networks
A 1D CNN is a variant of a convolutional neural network where convolution is performed along only one dimension. It processes the input data as a one-dimensional sequence, making it ideal for analyzing time series or one-dimensional signals such as audio recordings.
The image shows a sequence of frequency waves in an audio recording.
Source: Gaussian Waves
1D CNNs are composed of three main types of layers: convolutional layers, which convolve the input data with a set of trained filters; pooling layers, which reduce the spatial size of the input data; and fully connected layers, which perform classification or regression based on the learned features.
An example of convolution of a one-dimensional signal.
Source: Brandon Rohrer
Anomalies Detection in Time Series
Sensors that collect data in real-time often monitor manufacturing processes. This data can be analyzed using 1D CNN to detect anomalies such as unexpected changes in temperature, humidity, pressure, or other important parameters. Early detection of such anomalies helps to identify and eliminate problems in time, increasing production efficiency and reducing losses.
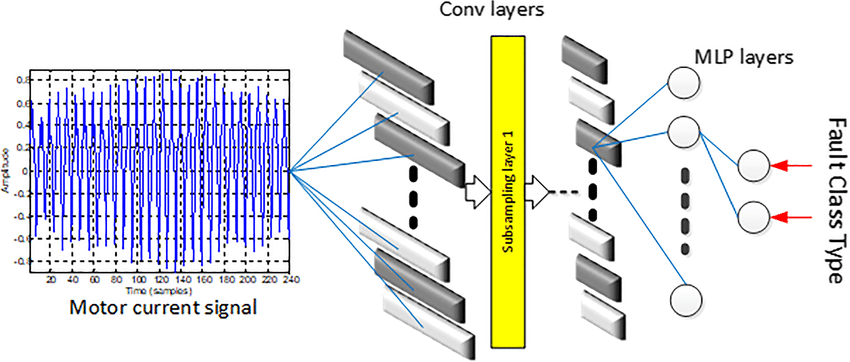
An example of a model based on single-layer neural networks for detecting malfunctions in motors in production.
Source: Researchgate
Energy Use Prediction
1D convolutional neural networks can be used to predict energy consumption. For example, based on a time series of previous energy consumption data, 1D CNNs can detect patterns and trends that predict future consumption. This can be useful for energy companies to optimize energy production and distribution. Below, you can see an example of what the data looks like for such tasks and the architecture used to solve such a task.
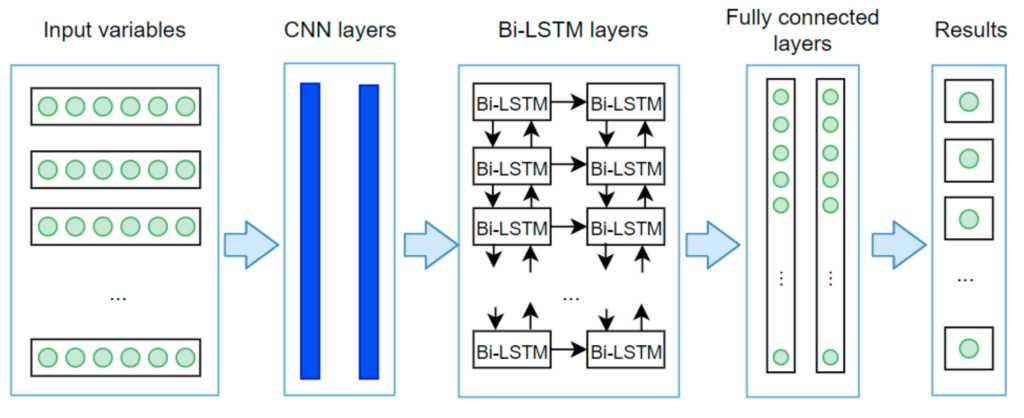
Source:MDPI
Speech Recognition and Audio Analysis
1D CNNs are also widely used in audio analysis. They can detect important characteristics in audio signals that can be used for speech recognition or music genre classification. For example, in speech recognition, 1D CNNs can analyze audio recordings of speech to identify specific sounds or words. In music genre classification, they can analyze music tracks to identify characteristics specific to a particular genre.
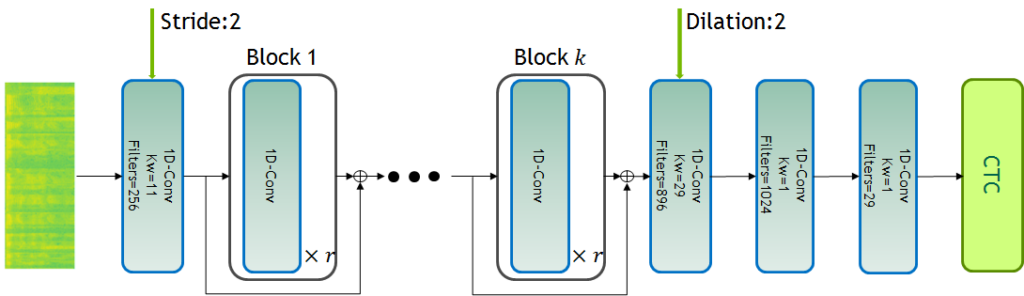
Jasper neural network architecture for speech-to-text tasks.
Source: Nvidia GitHub
Two-Dimensional Convolutional Networks
Two-dimensional convolutional neural networks (2D CNNs) are a key tool in computer vision. They use convolution to detect spatial properties in input data, which makes them particularly effective for image analysis. These networks help solve many tasks, including image classification, object detection, semantic segmentation, etc.
Image classification
2D CNNs are the standard choice for image classification tasks. Image classification is determining the category to which an image belongs. For example, image classification can include determining whether a photo shows a cat, dog, person, or car. This is an important task in computer vision and machine learning, as models that perform well here are likely to perform better in other computer vision tasks.
Convolutional Neural Networks (CNNs) are used to solve the problem of image classification because they effectively detect local and spatial patterns in data by applying appropriate filters. As in the case of working with signals, CNNs for image classification consist of two main parts:
- Feature detection stage: During this stage, the CNN performs convolution, nonlinear activation (e.g., ReLU), and pooling (or subsampling) operations on the input image to detect spatial hierarchical patterns such as edges, textures, shapes, etc.
- Classification stage: After the feature detection stage, CNN uses fully connected layers to classify images based on the detected features. These layers are similar to those used in conventional neural networks.
It is worth noting that CNNs require a large amount of data for training and a significant amount of computing resources to be effective.
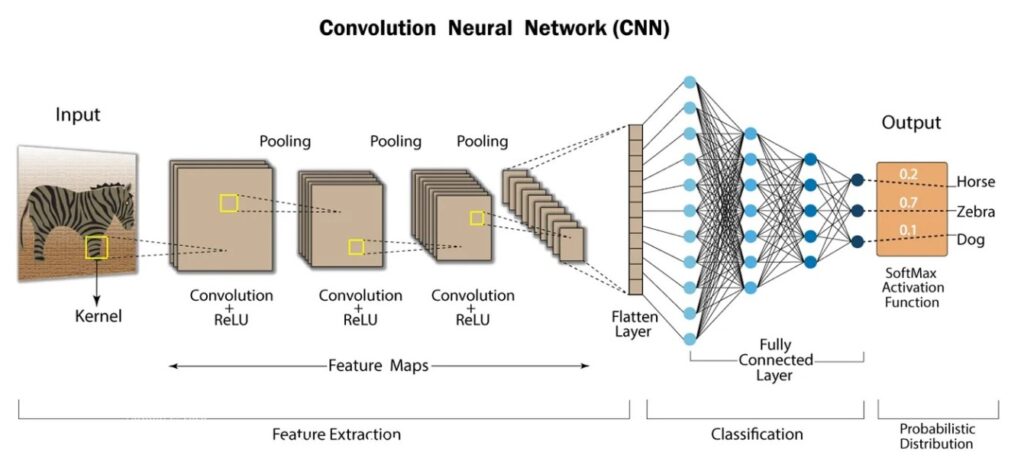
This is an example of the architecture of a convolutional neural network for image classification, which consists of convolutional layers and fully connected layers of classical artificial neurons.
Source: LinkedIn
Object Detection
Object detection is the process of identifying and locating objects in an image. The task is to determine the object's class and obtain the exact coordinates of its location.
CNN-based neural networks play an important role in object detection. They identify features in an image that help identify and locate objects. Convolutional layers in CNNs effectively detect various features, leading to accurate object detection.
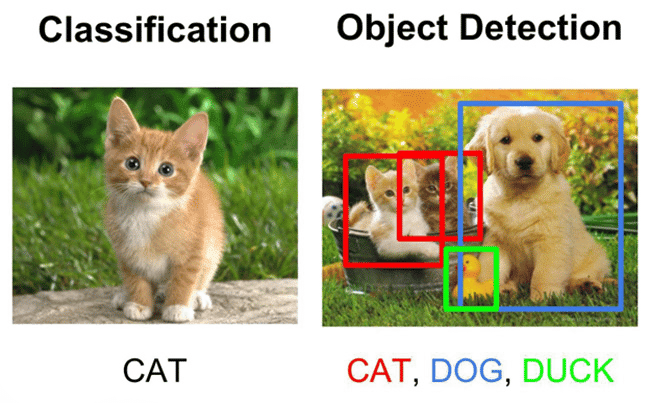
An example of how the classification task differs from the object detection task.
Source: Ambolt AI
Examples of neural network architectures that solve these problems include YOLO and Faster R-CNN.
YOLO (You Only Look Once) is distinguished by its ability to perform object detection and classification in one pass, which makes it extremely fast. YOLO divides the image into a grid, providing each cell's bounding boxes and class probabilities.
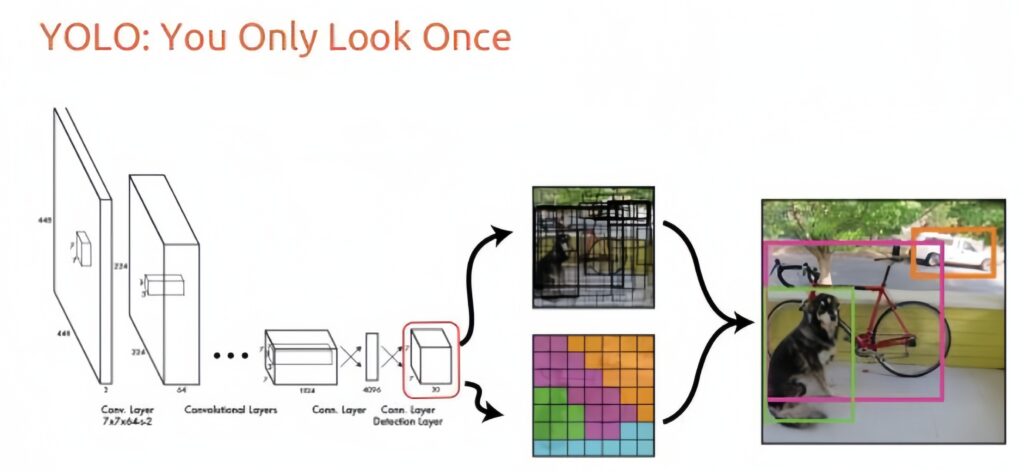
An example of how the YOLO algorithm works.
Source: Analytics Vidhya
Faster R-CNN: This model uses two modules - a regional convolutional neural network to generate regions of interest (RoIs) and a fully connected network to classify and refine these regions.
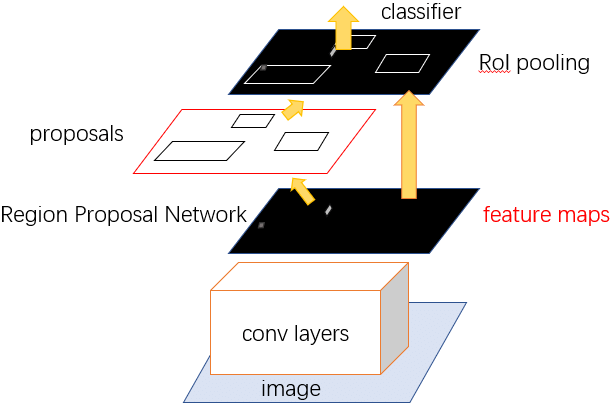
Source: Researchgate
Both models are widely used to solve similar problems or are the basis for solving them.
Semantic Image Segmentation
Semantic segmentation determines whether each pixel in an image belongs to a particular class. It determines the class of objects in the image and accurately defines their boundaries at the pixel level.
CNN-based neural networks play a key role in semantic segmentation. As in the previous tasks, they are used to identify features in the image that help identify and segment objects. Convolutional layers in CNNs effectively detect local and global features in an image, which helps accurately identify objects and their boundaries.
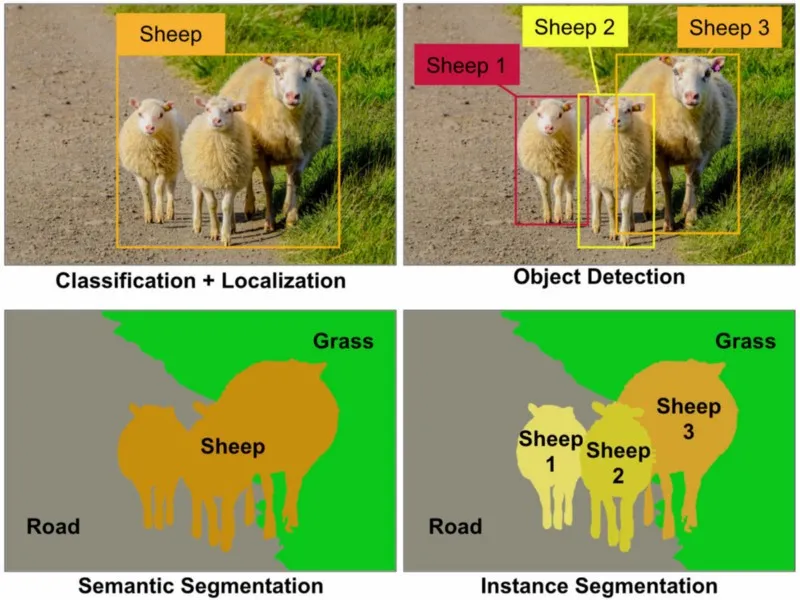
An example of how segmentation tasks differ from classification and detection tasks.
Source: Medium
Let us consider several popular architectures, namely U-Net and FCN, as examples for solving this problem.
U-Net: This architecture consists of a “compressing” (encoder) and “expanding” (decoder) part that form a “U” shape. The encoder is used to identify image features, while the decoder uses these features to build a segmented image, i.e., it provides a class for each pixel in the image. A special feature of U-Net is the presence of “bridges” between the encoder and decoder, which allows you to transfer contextual information to the decoder.
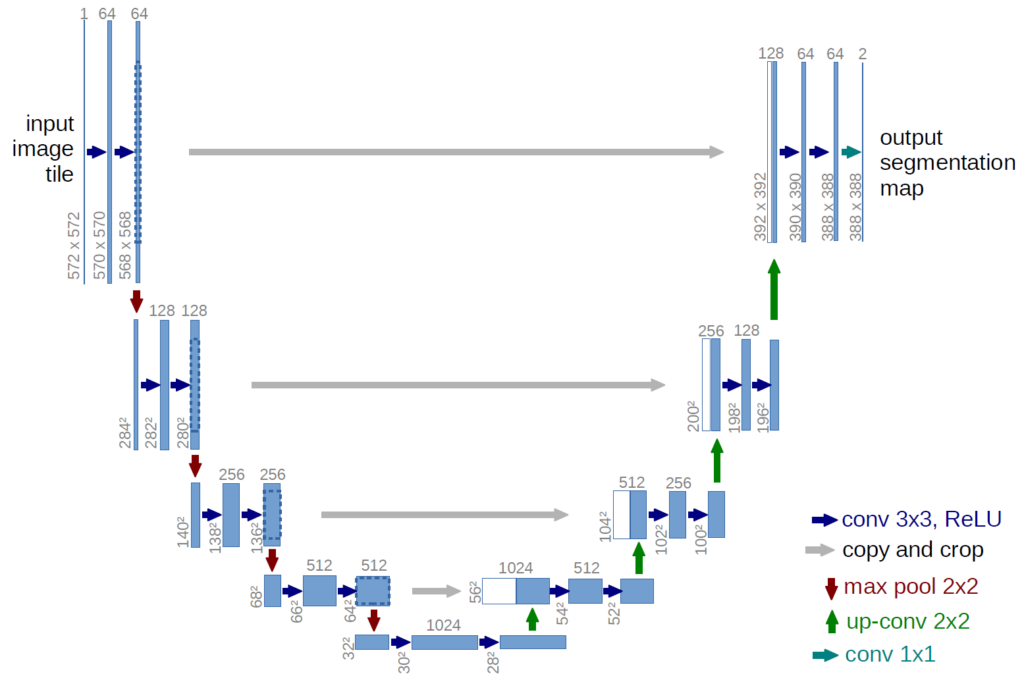
The convolutional layers in U-Net transmit information to all subsequent layers and those at the opposite “end” of the model. That is, the first layer passes information to the last, the second to the penultimate, and so on.
Source: UNI Freiburg
FCN (Fully Convolutional Network): Unlike traditional CNNs, which use fully connected layers for classification, FCN converts these layers into convolutional layers, which allows processing images of any size and outputting a semantic map that matches the size of the input image.
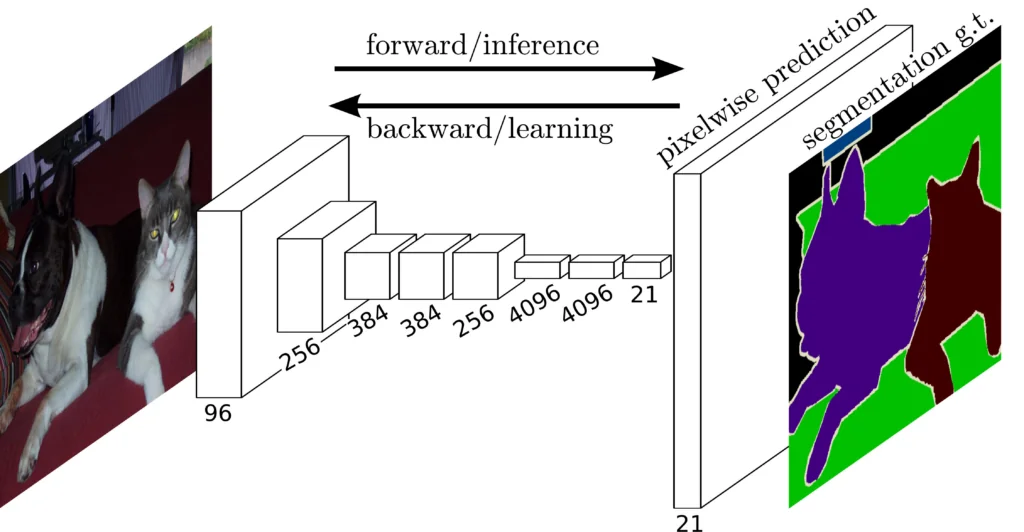
FCN uses filters comparable in size to the original image as the penultimate layer.
Source: Papers With Code
Three-Dimensional Convolutional Networks
So far, we've discussed one-dimensional and two-dimensional neural networks, and now we need to examine three-dimensional ones. Let's briefly recall the ones we have already covered to understand the new type of convolutional networks better.
One-dimensional convolutional operations analyze data sequences, such as time series. They traverse the data in one direction, identifying features within a defined “window” area.
Two-dimensional convolutional operations are used to analyze two-dimensional data, such as images. They traverse the data in two directions (width and height), identifying features within a defined windowed area.
3D convolutional operations, such as video or 3D scans, analyze three-dimensional data. They traverse the data in three directions (width, height, and depth), identifying features within a defined “cubic” area.
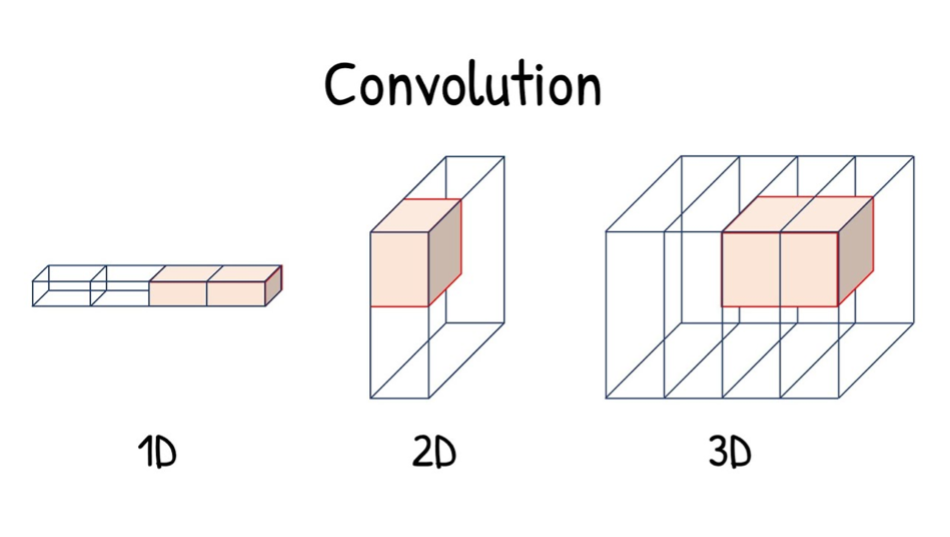
Source:YouTube
Applications of 3D neural networks are usually very specific, but in some cases, they are indispensable.
Brain Disease Classification
3D convolutional neural networks can be used to analyze 3D brain scans to classify brain diseases. They can identify features in three-dimensional space to detect abnormalities such as tumors.
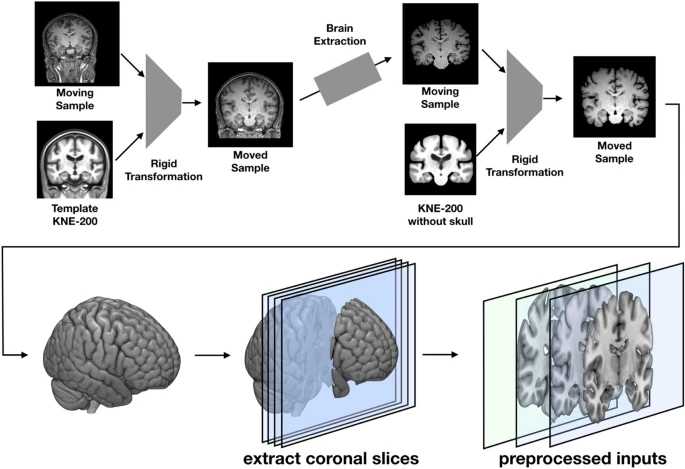
Source: Nature.com
Action Recognition
Action recognition is a computer vision task that involves identifying specific actions performed in a video. It can recognize human actions such as walking, running, jumping, swimming, throwing objects, etc.
3D-CNNs are ideal because they can analyze video in time, considering spatial and temporal differences between frames. This allows the models to learn and recognize complex actions that are located in time.
Three-dimensional convolutional neural networks can analyze and detect complex actions or behaviors over time.
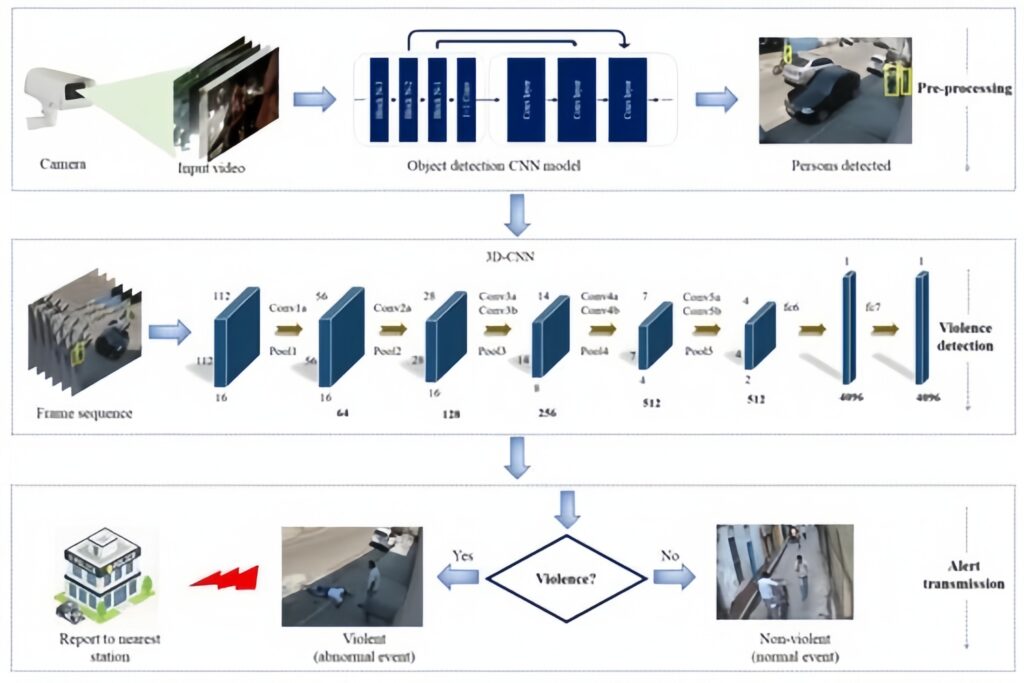
An example is a limited number of frames fed into a three-dimensional neural network to predict the action in the video.
Source: MDPI
The current state of CNN
The world of artificial intelligence and deep learning is striking in its dynamism and novelty, especially when using convolutional neural networks (CNNs). One of the most exciting applications of CNNs is image generation, which generates new, realistic images based on learning from large datasets. This process covers everything from creating original content to modifying existing images.
Image generation
Diffusion models have become key in image generation, using an innovative approach based on the backward diffusion process. This method is based on the gradual transformation of noise into the final image through a series of diffusion steps. Each step aims to bring the noise closer to the real data distribution. Simply put, these models remove noise from the image.
This process is iterative, and with each new step, the model introduces more reality-reflective details into the original noise. This extremely powerful tool opens up new possibilities for generating realistic images and other types of content. It uses a neural network based on U-Net, built using two-dimensional CNNs.
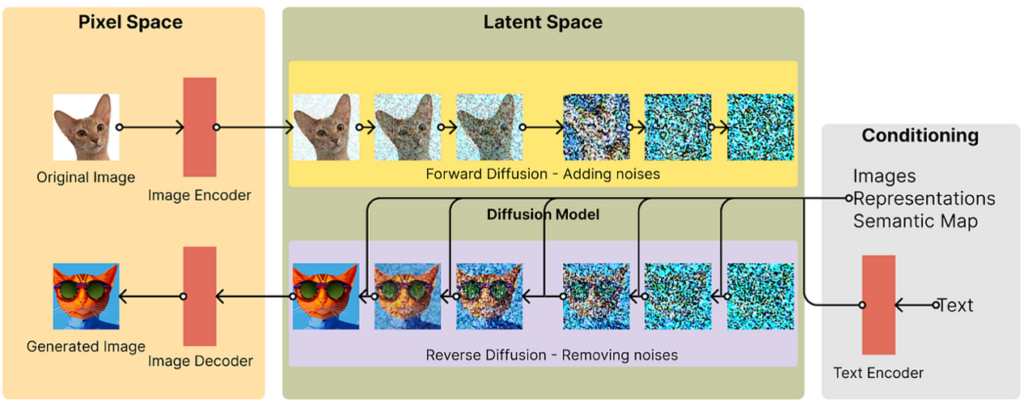
The image that falls into the diffuse model is reduced in size, moving into the so-called latent space, after which noise is added by a certain number of steps. A textual instruction or query removes noise from the “Conditioning” block, forming a matrix that transforms from latent space into a full-fledged image.
Source: Medium
The most prominent representatives of this type of algorithm are Stable Diffusion, DALL-E and Mid Journey. These models combine both the textual representation of information to develop large language models (LLMs) and the ability of convolutional layers to find and localize details in images.

Stable Diffusion v3
Source: Stability.ai

MidJourney v6
Source: Dataconomy

DALL-E 3
Source: Improving Image Generation with Better Captions
Video Generation
Diffusion models are also used for video generation. The video is treated as a sequence of frames, and the model works with each frame separately, enriching the noise with details and structure. The algorithm covers high-level characteristics such as the video script, object dynamics, and other important elements. The details of how the video will look and its characteristics, characters, and scenarios can be edited by text query.
The process is iterated until the model generates a video using the same U-Net-based CNNs corresponding to the real data distribution. This opens up new possibilities for creating realistic videos from scratch. At the time of this writing (February 2024), many models with such capabilities have been released, the most famous of which are Stable Video, SORA, and EMO.
The first two simply generate high-quality still images based on text queries, while Sora's capabilities allow you to make videos of any dimension without losing quality. Here's an example of Stable Video and SORA:
The EMO model takes as input a human image and audio that a person is supposed to voice.
Multimodal Models
An important step forward in generative models is multimodal models, which use CNNs to process multiple input types, such as text, images, and sound. Multimodal models open up new possibilities for creating more complex and flexible AI systems.
The main principle of multimodal models is their ability to combine information from different sources or modalities (sound, image, text, temperature, movements, etc.), which allows for more complete and accurate information output.

An example of using multimodal models to predict real estate prices. The input to the neural network is data in three modalities: real estate images, textual descriptions of real estate, and structured information in tables about this real estate.
Source: Medium
Multimodal models can involve translating one modality into another, such as translating text into an image or using combinations of modalities to improve understanding of a context or task. Examples include all the previous models for generating images and videos, which can receive text and images as input. One of the most interesting multimodal models is ImageBind. It can convert a text query into an image, audio, or video into a text description, audio, heat map, and depth map. This model also offers various combinations of similar conversions from one modality to another between text, video, image, heat map, depth map, and motion map.

Source: Meta
Autonomous Vehicles
CNN has also influenced the world of autonomous vehicles. CNN has become a key tool in developing self-driving systems for cars, drones, and other vehicles because it can recognize and interpret visual information in real-time. CNN processes three-dimensional data, including video from cameras and other sensors, to identify objects in space and time.
Such algorithms include identifying other cars, pedestrians, road signs, and lane lines. In addition, 3D-CNNs can be used to analyze video sequences, determine the dynamics of objects and predict their future behavior. This is important for the safe driving of autonomous vehicles, as they must be able to predict the actions of other road users.
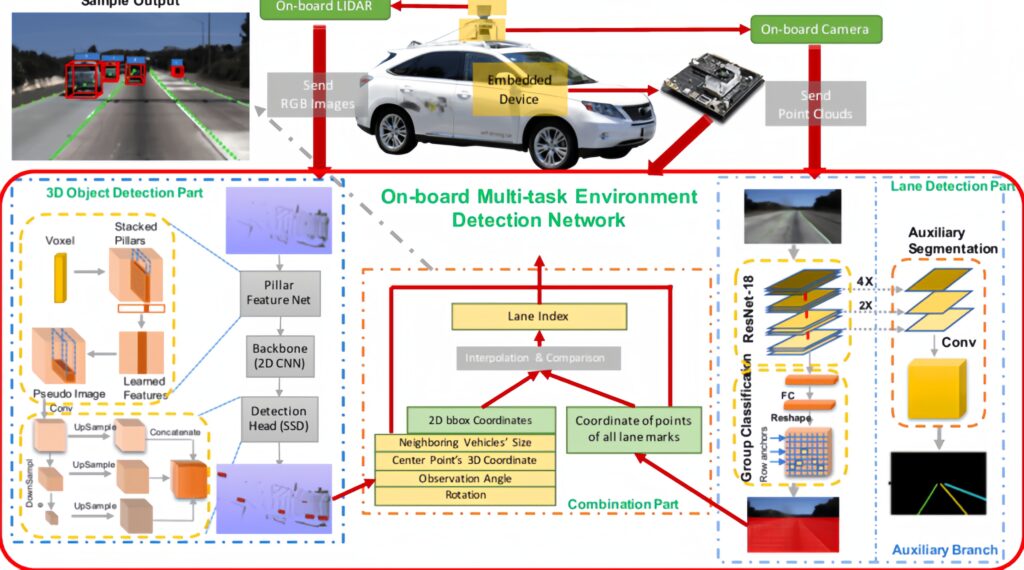
As you can see, the car simultaneously solves several tasks related to computer vision. The autopilot algorithm receives data from cameras and motion sensors (lidars) and determines the car's position in the lane, recognizing 3D objects around the car. Based on this information, the system decides how to behave.
Source: Researchgate
Conclusion
Even though CNNs differ in their use, models, and tasks, they are efficient in accuracy and computation speed. At the same time, the mathematical basis for each of these models is the same. They can detect patterns at different abstraction levels, making them effective for object recognition, image segmentation, and generating new images and videos.
However, CNNs are not limited to these cases. They can also be combined with other models to create multimodal systems that simultaneously process several data types. This opens up new opportunities for creating more complex and intelligent information processing systems.
It is also worth noting that CNNs are still evolving. Breakthroughs in deep learning and computer vision, such as diffusion models, provide new opportunities to improve CNNs' accuracy, speed, and efficiency in image processing.
This article is not exhaustive, as there are various variations of CNNs, including depthwise convolution, upscale convolution, convolution in GNNs, and others that have not been considered. These approaches modify convolutional neural networks to optimize them for specific tasks or data types.
Mastering these specialized variants of CNN can enable you to develop more efficient and accurate models for processing images and other data types. Therefore, if you are interested in deep learning and image processing, these topics can be very useful for exploring further.
In the next article, we will formalize the process of applying convolutional layers and training them in detail. I recommend reading it if you are interested in CNN mathematics and how the convolutional neural network algorithm is built.



