

Convolutional neural networks (CNN) are one of the most innovative approaches in AI, in particular in the field of computer vision. Convolutional neural networks first gained widespread attention in 2012, when Alex Krizhevsky and Ilya Sutskever won the ImageNet contest using CNN by reducing the number of classification errors from 26% to 15%. Convolutional networks are now successfully used by the leading IT companies in the world, such as Amazon, Google, Facebook, Interest, and Instagram. CNN is used for speech recognition, audio processing, time series processing, analyzing the meaning of texts and developing algorithms for playing Go. At the moment, it is one of the most successful models, the most successful innovation in the area of deep learning.
Let's look at what principle lies in the idea of creating convolutional networks, which frameworks support them, and how to integrate all this into the cloud system to solve modern practical problems.
Neural Networks as a computational model
As we mentioned in the previous article “How to build a neural network on Tensorflow for XOR”, artificial neural networks (ANNs), or connectionist systems, are computing systems inspired by the biological neural networks that make up the brains of animals. Such systems use training tasks (progressively improving their performance on them) by examining examples. The process of computation generally goes without special programming.
ANN is based on a set of connected nodes called artificial neurons (similar to biological neurons in the brains of animals). Each connection (similar to a synapse) between artificial neurons can transmit a signal from one to the other. The artificial neuron receiving the signal may process it and then signal to the artificial neurons attached to it. Neural networks are now widespread and are used in practical tasks of speech recognition, automatic text translation, image processing, analysis of complex processes and so on.
Convolutional Neural Network
A publication by Hubel and Wiesel in the 1950s and 1960s showed that in the brains of cats and monkeys visual cortexes contain neurons that individually respond to small regions of the visual field. This discovery in biology triggered the creation of artificial neural networks.
Convolutional neural network (CNN) is a special architecture of artificial neural networks, proposed by Jan Lekun (Bell Labs) in 1988 and aimed at efficient pattern recognition, which is part of deep learning technologies. It uses some features of the visual cortex, in which the so-called simple cells, which react to straight lines at different angles, and complex cells, the reaction of which is associated with the activation of a certain set of simple cells, were discovered. Thus, the idea of convolutional neural networks is to alternate convolution layers and subsampling layers or pooling layers. The network structure is unidirectional (without feedbacks), basically multilayer.
For training convolutional networks standard methods are used, most often the method of backpropagation of errors. The activation function of neurons can be any, according to the choice of constructing a model of a neural network.
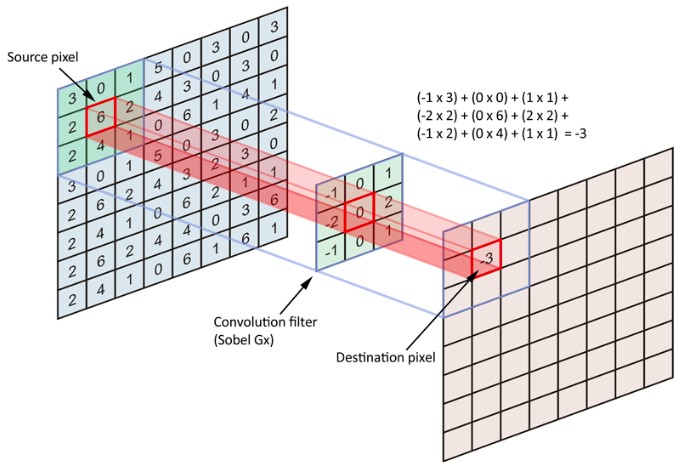
The network architecture got its name because of the convolution operation, the essence of which is that each image fragment is multiplied by the matrix (core) of the convolution element by element, and the result is summed and written to the same position in the output image.
Fig. 1. Convolution of two functions
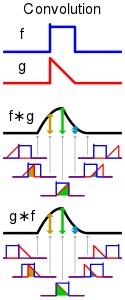
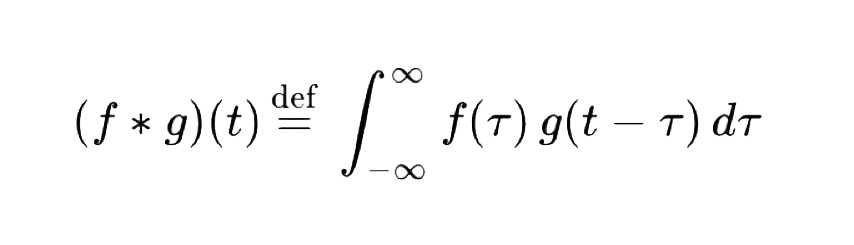
The convolution network architecture is based on perceptrons, like all other neural networks. In an ordinary perceptron, which is a fully connected neural network, each neuron is connected to all neurons of the previous layer, and each connection has its own personal weight coefficient.
In the convolutional neural network, the convolution operation uses only a limited matrix of small-sized weights that are “moved” throughout the processed layer (at the very beginning - directly in the input image), forming an activation signal for each next layer neuron with a similar position after each shift.
For different neurons of the output layer, the same weight matrix is used, which is also called the convolution core. It is interpreted as graphic coding of a feature, for example, the presence of an inclined line at a certain angle. Then the next layer, resulting from the convolution operation by such a weight matrix, shows the presence of this feature in the layer being processed and its coordinates, forming the so-called feature map.
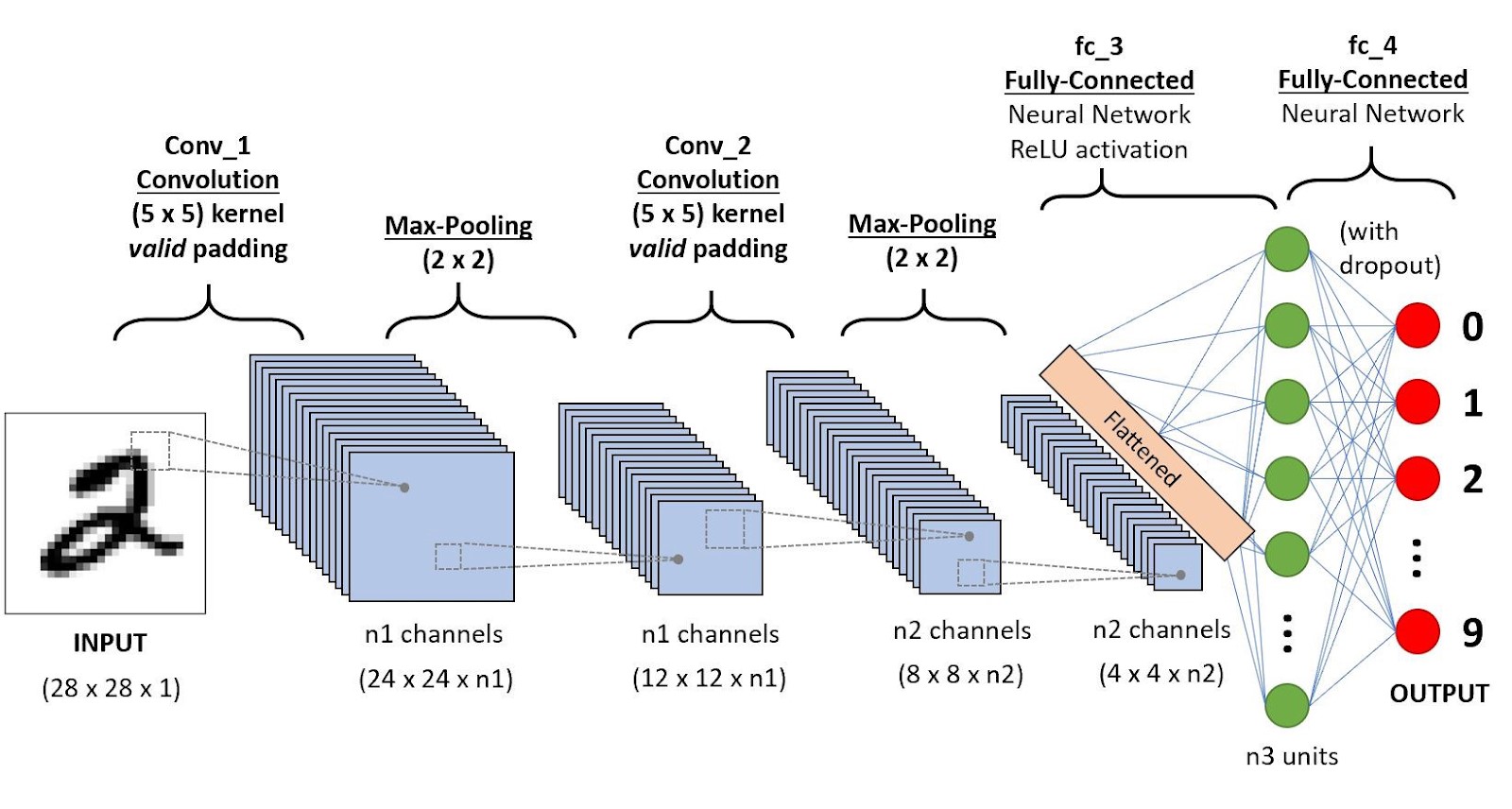
CNN consists of input and output layers, as well as several hidden layers. In the usual case, the convolution network consists of the following components:
- Convolution layer. The convolutional layers apply a convolution operation to the input, passing the result to the next layer. The convolution simulates the response of an individual neuron to the visual stimulus. Each convolutional neuron processes data only for its receptive field. The convolution operation solves the problem of a large number of inputs in images, since it reduces the number of free parameters, allowing the network to be deeper.
- Activation layer. Convolutional networks may include layers of local or global aggregation that integrate the outputs of clusters of neurons from one layer to one neuron of the next layer. The scalar result of each convolution falls on the activation function, which is a certain non-linear function. The activation layer is usually logically combined with the convolution layer (it is believed that the activation function is built into the convolution layer). The activation layer (most often using the simple activation function ReLU) gives you the opportunity to pass values from the previous layer through the activation functions. This determines the triggering or non-triggering of neurons when transmitting a signal to the next layer.
- Pooling or downsampling layer. A pooling layer (also known as subsampling) is nonlinear compaction of the feature map, while a group of pixels (usually 2×2 or 4x4) is compressed to one pixel through a nonlinear transformation. The pooling operation can significantly reduce the spatial volume of the image. The pooling layer is usually inserted after the convolution layer before the next convolution layer. Fully connected neural network. These data are combined and transmitted to a regular fully connected neural network, which can also consist of several layers. In this case, fully-connected layers already lose the spatial structure of pixels and have a relatively small dimension.
When training convolutional networks, there are some difficulties for which special training techniques have been developed. For example, since the degree of retraining a model is determined by both its power and the amount of training it receives, providing a convolutional network with more training examples can reduce retraining.
Because these networks usually train all available data, one approach is to either generate new data from scratch, if possible or augment existing data to create new data. For more information please read this article.
Advantages of Convolutional Neural Networks
Andrej Karpathy, now Sr. Director of Artificial Intelligence and Autopilot Vision at Tesla (PhD from Stanford University in 2015 under the supervision of Dr. Fei-Fei Li) found advantages of CNN on image recognition in work “Karpathy, Andrej, et al. «Large-scale video classification with convolutional neural networks.» IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2014” and others. This gave a huge impetus to the development of approaches to solving problems in computer vision using neural networks and, in particular, using CNN. Other scientists also noted the enormous potential for using CNN in the processing of audio and text information.
The advantages of using convolution networks:
- One of the best image recognition and classification algorithms.
- Compared with a fully connected neural network (such as a perceptron), there are many fewer customizable weights, since one core of the weights is used entirely for the entire image, instead of having its own personal weighting factors for each pixel of the input image. This encourages the neural network to generalize the information displayed during training, rather than per-pixel memory of each shown image in a myriad of weighting factors, as the perceptron does.
- Convenient parallelization of calculations, and therefore the ability to implement work algorithms and network training on GPUs.
- Relative resistance to rotation and shift of the recognized image.
- Training using the classic backpropagation method.
Disadvantages inherent in convolutional neural networks:
- There are too many variable network parameters; it is not clear what settings are needed for what task or computing power. Variable parameters include the number of layers, the convolution core dimension for each layer, the number of cores for each layer, the core shift step when processing the layer, the need for sub-sampling layers, the degree of dimension reduction, the function of reducing the dimension (choosing the maximum, average and etc.), the transfer function of neurons, the presence and parameters of an output fully connected neural network at the output of a convolutional one. All these parameters significantly affect the result but are selected empirically by the researchers.
- There are several verified and perfectly working network configurations, but there are not enough recommendations on which to build a network for a new task.
The applications of convolutional networks are very wide and are most popular in:
- Image recognition
- Video analysis
- Natural language processing
- Search for new medical substances
- Simulation of complex games (Checkers, Go)
There are pre-built popular convolutional neural network models that can be used for solving various real-world problems: LeNet, AlexNet, VGGNet, GoogLeNet, ResNet, ZFNet and others. For more information about these models, please read this article.
CNN Implementations in frameworks
The time has already passed when it was necessary to write an implementation of a neural network from scratch in a programming language like C++, Java, Python, or JS. Now you have a large selection of frameworks at your disposal, where you can build the necessary configuration of a neural network with the required number of inputs, outputs, layers, activation functions, error estimates, etc. And most importantly, frameworks now provide training tools for neural networks using the latest fast methods. Basically, these methods are based on the use of gradients of the error estimation function, which makes it possible to quickly and efficiently train your convolutional network to solve the problem.
Caffe: A library for convolutional neural networks, created by the Berkeley Vision and Learning Center (BVLC). It supports both CPU and GPU and was developed in C++, and has Python and MATLAB wrappers.
Deeplearning4j: Deep learning in Java and Scala on multi-GPU-enabled Spark. A general-purpose deep learning library for the JVM production stack running on a C++ scientific computing engine. It allows the creation of custom layers and integrates with Hadoop and Kafka.
Dlib: A toolkit for making real-world machine learning and data analysis applications in C++.
Microsoft Cognitive Toolkit: A deep learning toolkit written by Microsoft with several unique features enhancing scalability over multiple nodes. It supports full-fledged interfaces for training in C++ and Python and has additional support for model inference in C# and Java.
Tensorflow: Apache 2.0-licensed Theano-like library with support for CPU, GPU, Google's proprietary tensor processing unit (TPU), and mobile devices.
Theano: The reference deep learning library for Python with an API largely compatible with the popular NumPy library. Allows the user to write symbolic mathematical expressions, then automatically generates their derivatives, saving the user from having to code gradients or backpropagation. These symbolic expressions are automatically compiled to CUDA code for a fast, on-the-GPU implementation.
Torch: A scientific computing framework with wide support for machine learning algorithms, written in C and Lua. The main author is Ronan Collobert, and it is now used at Facebook AI Research and Twitter.
Keras: A high-level API written in Python for TensorFlow and Theano convolutional neural networks.
Support CNN in Cloud AI frameworks
Today we have access to many cloud services that support work in convolutional neural networks. Users of such cloud systems can efficiently develop, deploy and support large AI systems using convolution networks.
At the same time, many useful properties of using cloud technologies will be present, especially scaling. From an economic point of view, cloud systems allow you to effectively spend money on a project, even when using nodes using a GPU, which is very useful when training convolution networks.
Cloud AI, Google Cloud. Google Cloud AI Platform, our code-based data science development environment, lets ML developers and data scientists quickly take projects from ideation to deployment.
Machine Learning on AWS. AWS has the broadest and most comprehensive suite of machine learning and AI services for your business. In AWS, you can choose one of the pre-trained AI services for working with computer vision, languages, recommendations, and forecasts. Using Amazon SageMaker, you can quickly create, train, and deploy scalable machine learning models, or create custom models that support all of the popular open source platforms.
Deep Learning Toolbox - MATLAB - MathWorks. Neural networks are inherently parallel algorithms. Deep Learning Toolbox povides the advantages of neural network parallelism by Parallel Computing Toolbox to distribute training across multicore CPUs, graphical processing units (GPUs), and clusters of computers with multiple CPUs and GPUs. Working in the cloud requires some initial setup in the Deep Learning Toolbox, but after the initial setup using the cloud, you can greatly reduce training time.
Microsoft Azure - The Microsoft Cognitive Toolkit. Microsoft provides various approaches for working with AI in the cloud. Azure has the Microsoft Cognitive Toolkit, aslo known as CNTK. It allows training a convolutional neural network over multiple nodes and multiple GPUs. Great performance in the cloud is possible by using CNTK, which achieves almost linear scalability through advanced algorithms such as 1-bit SGD and block-momentum SGD.
IBM Watson Machine Learning Studio. Watson Studio provides the environment and tools to solve your business problems by collaboratively working with data. A powerful part of IBM Machine Learning Studio is Watson Machine Learning. It provides a full range of tools and services for building, training, and deploying Machine Learning models. Watson Machine Learning has many great features, including Synthesized Neural Network and Neural Network Modeler.
Conclusion
And so, in the modern world of AI, convolutional networks have found their application and reliably solve problems in many applied fields, for example, image processing, video, texts, audio information, and analysis of complex processes in economics and sociology.
Convolutional network models are constantly evolving and allow solving both new types of problems and improving existing solutions. We already use many of them in practice without even thinking, saying "OK, Google" or "Alexa, switch on the light". On the basis of convolutional networks, a new architecture of neural networks will be developed, and in combination with other methods, better solutions to urgent problems will appear.



