
Data quality monitoring rarely gets attention until something breaks. It shows up as a dashboard that doesn’t match financial records, a customer segmentation model that starts sending premium offers to churned accounts, or an AI chatbot that confidently answers questions using stale data.
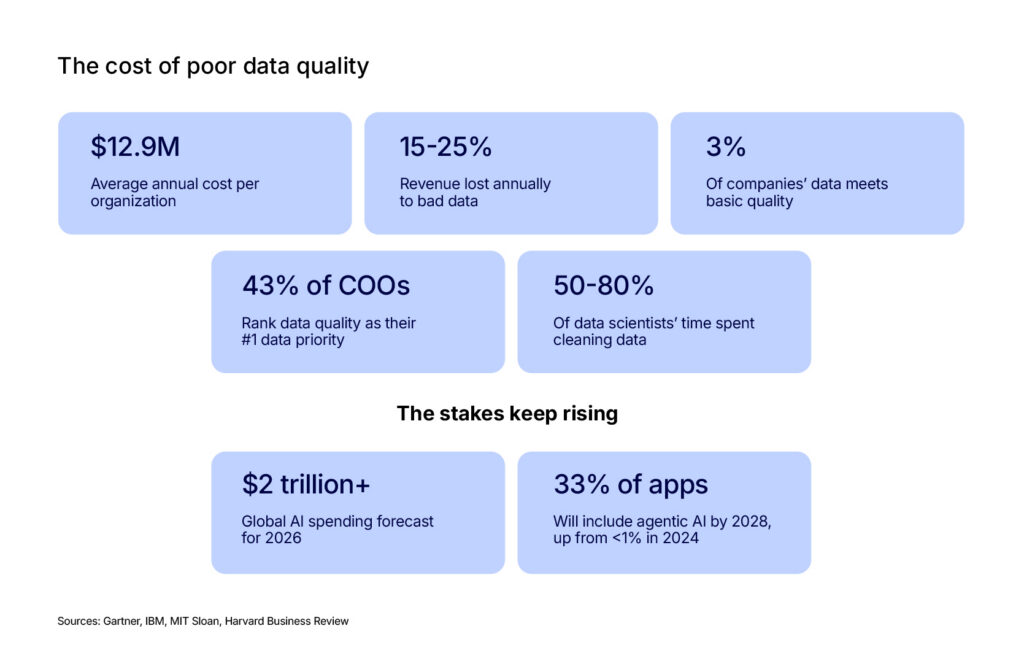
Poor data quality is an expensive problem. Gartner estimates it costs organizations an average of $12.9 million annually. IBM found that 43% of COOs consider data quality their top priority, as many companies lose over $5 million each year. Alarmingly, Harvard Business Review reports that only 3% of corporate data meets basic quality standards.
The problem continues because manual, small-scale data quality rules don't work for today's large-scale data infrastructure with thousands of tables and complex AI pipelines.
Let's explore why traditional approaches break at scale, how agentic AI is applied, and what it takes to build a data quality practice that scales.
The Real Cost of Bad Data in the AI Era
Data quality means your data accurately reflects reality. Your data should meet five long-standing dimensions: precision, completeness, consistency, timeliness, and validity. The framework hasn't changed, but the consequences of poor quality have.
Small errors in spreadsheets affect single reports, but errors in AI training data impact every future prediction. A 2025 IBM report put it this way: when AI investment scales, the cost of poor data quality scales with it.
The financial picture is bleak. A study by MIT Sloan and Cork University Business School found that companies lose between 15% and 25% of their revenue annually due to poor data quality. Gartner puts the average annual cost at $12.9 million per organization. And those figures predate the current wave of generative AI adoption. With global AI spending forecasted to surpass $2 trillion in 2026, the exposure is getting larger.
The damage is often invisible. A stale CRM record or duplicate inventory entry doesn't trigger an error. It quietly misleads lead-scoring models or causes stock imbalances. By the time someone traces the issue, weeks of faulty decisions have already been made. IBM research calls this the "insidious effect," where poor data quality gradually shapes strategic decisions long before anyone identifies the root causes.
Beyond the finances, bad data erodes internal trust. When employees don't trust the numbers, they fall back on gut instinct or their own makeshift solutions. Sales teams ignore unreliable lead scores, and data teams lose credibility when models fail. Accenture research shows that only a third of executives trust their data enough to make decisions from it. This trust deficit is a direct consequence of unaddressed quality failures.
Data quality has always been a known issue, but the speed of AI has upped the ante. Since AI agents now make autonomous decisions in real-time, the gap between a data error and its impact has shrunk from weeks to minutes. Traditional quarterly audits are no longer fast enough to prevent damage.
Why Traditional Data Quality Management Falls Apart at Scale
Most organizations still manage data quality as they did a decade ago. Engineers manually write rules for critical tables, checking for null values or refresh times, and respond to alerts when they trigger. However, as data estates grow, this manual approach becomes impossible to maintain.
Manual data quality rules fail because modern systems have hundreds or thousands of tables with shifting patterns. At that volume, manual rules can’t scale. Relying on static checks causes “alert fatigue” from false alarms or results in missed critical failures. Since data scientists already spend 50% to 80% of their time cleaning data, adding manual monitoring on top is simply not sustainable. That’s why the process needs to be updated.
Manual monitoring also fails because it treats tables in isolation. In reality, data flows in a chain. A failure in one upstream table cascades through every downstream report and model. Without visibility into these dependencies (data lineage), teams cannot prioritize fixes and often waste time on minor alerts while critical systems fail.
Traditional data quality methods fail to scale with modern data systems because teams often rely on manually defined rules. Traditional methods create major blind spots in the overall health of expanding data estates.
How Agentic AI Changes Data Quality Monitoring
The shift from manual rules to agentic data quality monitoring is easier to understand through a specific example:
A retail company with 2,000 data tables uses a traditional manual approach. Data engineers write and constantly update validation rules and thresholds for every table. At 30 minutes per table, the initial setup would take 1,000 hours before a single data anomaly is ever caught.
Agentic monitoring simplifies this by having AI agents learn a table's normal behavior (refresh times, row counts, and data distributions) from historical data. The system then automatically flags any deviations, figuring out the baseline on its own without the need for manual rules.
Root cause tracing is another area where agentic monitoring provides one of its biggest advantages. Beyond simply detecting an anomaly, the system identifies why it happened by tracing issues back through the data lineage. Whether a failure stems from a pipeline failure or an upstream schema change, this capability transforms monitoring from a simple notification system into a powerful resolution tool.
Agentic monitoring improves visibility, but it has clear limitations. It requires historical data to establish a baseline, meaning new tables won't benefit immediately. It only detects deviations from the baseline, so it cannot catch data problems that have always existed (it assumes the poor data is 'normal'). Agents can flag anomalies (like a sudden null rate change), but human domain knowledge is still required to determine if the event is a pipeline failure or a legitimate change in the data.
The broader market is quickly adopting agentic AI. Gartner predicts that 33% of enterprise applications will include agentic AI by 2028, a large jump from less than 1% in 2024. Data quality monitoring is a natural first use case for agents (observe, learn, detect, and escalate). The main challenge is shifting teams from writing manual rules to training agents.
Computer Vision in Real-Time Quality Control
Data quality isn't confined to databases and pipelines. In manufacturing, "data" is the physical product on the line, and quality control has traditionally depended on human inspectors catching defects by eye. That approach has the same scaling problem as manual data rules in a warehouse: it works at low volumes, but it breaks under the demands of modern production lines.
Computer vision in real-time quality control replaces that bottleneck with ML models trained to detect defects at production speed. A camera captures an image of every unit on the line. A classification model evaluates the image against thousands of examples of acceptable and defective products. The system flags or rejects units that fall outside tolerance in milliseconds, faster than any human inspector could manage.
A computer vision model is only as good as the images it was trained on. If the training set doesn't include enough examples of rare defect types (a scratch that only appears under certain lighting conditions, a material flaw that's invisible from one angle but obvious from another), the model will miss those defects in production. Building a training set that covers the full range of failure modes requires careful annotation, often by quality engineers who understand what they're looking at, not general-purpose labeling teams.
Where this gets interesting is the intersection with agentic AI. A standalone inspection system catches defects. An agentic system goes further.
It correlates defect patterns with upstream production variables (machine temperature, material batch, operator shift, time since last maintenance) and identifies the root cause of quality failures, not just the failures themselves.
If a particular machine starts producing a higher rate of defects after a tooling change, an agentic system can flag the correlation and recommend corrective action before the defect rate triggers a production stop.
The connection between physical quality control and data quality monitoring isn't accidental. Both problems share the same structure: a growing volume of "data" (whether rows in a table or products on a line), a need for automated detection that scales beyond manual inspection, and a pattern where the real value comes from tracing problems to their source rather than just catching symptoms.
Will AI Take Over Data Analytics?
Data analytics already relies on AI for repetitive, mechanical work. AI handles these tasks faster, more consistently, and without getting bored. For example:
- Databricks’ Genie lets users query data in plain English instead of writing SQL.
- Salesforce’s Tableau AI generates predictive models and scenario simulations through natural language prompts.
- GitHub Copilot writes boilerplate data processing code.
Strategic tasks require domain knowledge, experience, and contextual reasoning that current AI models don’t have. A language model can summarize a dataset. It can't tell you that the sales spike in Q3 was driven by a one-time contract that won't repeat, or that the customer churn numbers look artificially low because the definition of "active customer" was quietly changed last quarter.
While AI boosts analyst productivity, removing human judgment too quickly is dangerous. On one hand, AI copilots free analysts to explore hypotheses, test more scenarios, and produce deeper analyses. On the other hand, over-automation can silently spread errors for months, and detection systems may act on false positives without human oversight.
AI isn’t eliminating the need for data analysts, but it is changing how they spend their time. As routine work becomes automated, analysts are focusing more on interpretation, judgment, and decision support. In practice, that makes the role more valuable, not less.
How to Build an AI Data Quality Practice That Scales
Most data quality initiatives begin with a crisis: a poor, board-facing report, a model delivering incorrect predictions, or a customer being targeted with outdated data. Essentially, something breaks, and a data quality project gets funded.
This pattern treats data quality as a reactive measure. Breaking away from this reactive model and into a proactive one means investing in a practice that evolves with the data estate. That shift requires a few deliberate choices:
Start With Governance, Not Tools
The most common mistake is purchasing a monitoring tool before establishing data ownership. Without clear data ownership, defined critical tables, and agreed response times, monitoring tools only flag problems without providing a path to resolve them.
According to Gartner, up to 75% of governance initiatives fail because of ambiguous ownership. Addressing these organizational questions first ensures that later investments in monitoring software are effective.
Invest in Lineage Early
Lineage tracks how data moves through your systems, from the sources that produce it to the dashboards and models that consume it. Without this map, every quality issue requires slow, manual investigation to find the source and assess the damage.
With lineage, a monitoring system identifies the problem and all affected downstream systems (dashboards, models, campaigns). This context enables prioritization based on business risk, changing a generic alert into an actionable incident.
Quality monitoring without lineage is like a fire alarm without a floor plan: you know something is burning, but not what's at risk.
Treat Monitoring as a Feedback Loop
Traditional quality checks run at fixed intervals: once a day, once a week, during a migration. That cadence made sense when data moved in batches. It doesn't hold when data streams continuously from dozens of sources, each on its own schedule.
The better approach is monitoring that takes place when data changes. Tables get checked when they update, not on a fixed clock. Anomalies are flagged in the context of the pipeline run that produced them, not in a daily summary email that arrives hours after the problem occurred.
The monitoring adapts to the data rather than running on a schedule that may or may not match reality.
Scale AI Data Labeling Without Sacrificing Quality
Data labeling has evolved from simple categorization to tasks requiring complex human judgment. Early tasks were simple, like tagging reviews as positive or negative. Today, AI systems require more detailed evaluation, such as checking whether a chatbot’s response is accurate, appropriate for the situation, and safe. Scaling the AI data labeling process without losing quality depends on layering three techniques:
- Machine-assisted pre-labeling. The ML model generates annotations automatically. Humans then review, correct, and refine those drafts. The model handles obvious cases, while humans focus on ambiguous ones.
- Active learning. Active learning identifies the examples where the model is least confident and routes those to human reviewers. This focuses on expensive human effort where it has the most impact on model performance.
- Consensus-based validation. Annotators label the same data point independently. When their labels agree, confidence is high. When they disagree, the discrepancy gets flagged for review. This approach surfaces ambiguities before they spread.
Build for the Team You Have
Most organizations lack a dedicated data quality team, leaving data engineers and analysts to manage quality on top of everything else. Quality tools and processes must fit this reality by being easy to operate for non-dedicated staff. This requires monitoring that generates actionable alerts rather than noise, and clear escalation paths, so anyone on the team knows exactly what to do when something breaks.
Don’t Leave Data Quality Unsolved
When AI models and autonomous agents start making decisions based on data, every quality failure gets amplified across every system those models touch. The old approach of manual rules and periodic audits can't keep pace with data estates that grow by hundreds of tables per year. Here’s how modern tools are catching up:
- Agentic monitoring learns patterns instead of requiring handwritten rules for every table.
- Lineage-aware systems prioritize the problems that carry the most business risk.
- Root cause tracing connects anomalies to the specific pipeline failures that caused them.
If you're building data quality pipelines or ML monitoring systems and need engineering support that understands both the architecture and the domain, talk to Svitla's team. We help organizations build the data infrastructure that AI systems can trust.


