
The AI ecosystem is maturing, making operational costs more visible, particularly the energy consumption of inference and the increased security risks in agentic architectures. Now they're embedded in supply chains, risk models, and healthcare, and nobody's treating them as optional.
As they scale, technical leaders must recognize AI’s tangible infrastructure and operational limitations.
Agentic AI is powerful. However, while delegating building tasks to autonomous systems, it's important to remember that underlying material limitations do not disappear but simply scale out of sight.
These hidden risks become more urgent in code review and generation. When agents write and review code, they can bypass traditional security guardrails and introduce vulnerabilities that propagate across the system at scale.
To understand how to regain control over this AI-generated technical debt, we must first debunk the myth of the 'immaterial' cloud, moving us directly into a conversation about AI's tangible realities.
I’m Patricio Gerpe, a Senior AI Engineer and consultant with global experience in AI startups, applied research, and social-impact projects. Working in both high-compute and resource-limited environments led me to focus on inference efficiency and energy-aware systems.
The industry already has emerging security frameworks such as the OWASP LLM Top 10. What is still missing is a similarly practical engineering mindset around inference efficiency and operational sustainability. In this article, we will review five practical engineering practices to reduce inference waste and help teams build AI systems that remain efficient and sustainable in production.
The reality check: the materiality of AI
For too long, AI has been framed as a weightless abstraction, but real-world deployments are tightly bound by computing capacity, energy availability, and cooling infrastructure.
Beneath the sleek APIs, there is also a very real human layer: large workforces of data labelers and content moderators who continuously correct and curate model inputs and outputs so that systems appear “seamlessly intelligent.”
Research on “ghost work” documents how this invisible labor is often outsourced to workers in the Global South under precarious conditions. Some moderation and labeling pipelines reportedly pay only a few dollars per hour.
When we scale these systems, we are expanding a global supply chain for energy, water, and, in many cases, low-cost labor. Recent analyses indicate that, in many production deployments, inference can account for a larger share of total energy consumption than one-off training runs.
At the same time, the water required to cool data centers is substantial. Studies suggest that extended interactive workloads can consume hundreds of milliliters of water per multi-turn session, depending on the model and cooling infrastructure.
Simultaneously, as we move past simple ReAct (Reason-Act) patterns into continuous cognitive loops, orchestrated in frameworks like OpenClaw (Think -> Plan -> Act -> Observe), the risk surface expands.
By executing these loops through periodic background heartbeats, agents maintain temporal persistence. This persistence changes the threat model. Vulnerabilities such as indirect prompt injection or excessive agency stop being isolated at events and become persistent operational risks. If the system is physical, and its execution loops are continuous, how should we measure its efficiency?
This brings us to an uncomfortable conversation. One metric has become increasingly common in startup AI teams: “tokens burned.”
Tracking tokens as a proxy for system productivity has become standard practice. However, interpreting increased token usage as higher productivity is risky and can be misleading. While token count reflects the amount of computing resources consumed by the system, it does not measure the actual value delivered to users or stakeholders.
As architectures become more complex, a high token count can just as easily indicate inefficient model use, uncontrolled agent loops, or redundancies as it can real work performed. We must consciously differentiate between token consumption driven by necessary inference and signaling waste or poorly constrained workflows. Are we truly measuring value created, or simply measuring compute consumption?
Consider when an agentic workflow transforms a single user request into unpredictable internal inferences that inflate token usage.
Is a rising token count a true indicator of productive computation, or is it a vanity metric that hides inefficiencies? Recognizing the problem is only half the battle. To build reliable AI, we need better architecture. From a cybernetic perspective, resilience requires feedback mechanisms and proactive limits to prevent runaway resource use.
5 ways to build resilient agents
If you are looking to engineer these boundaries and ensure the long-term viability of your agents, I suggest implementing these five technical strategies:
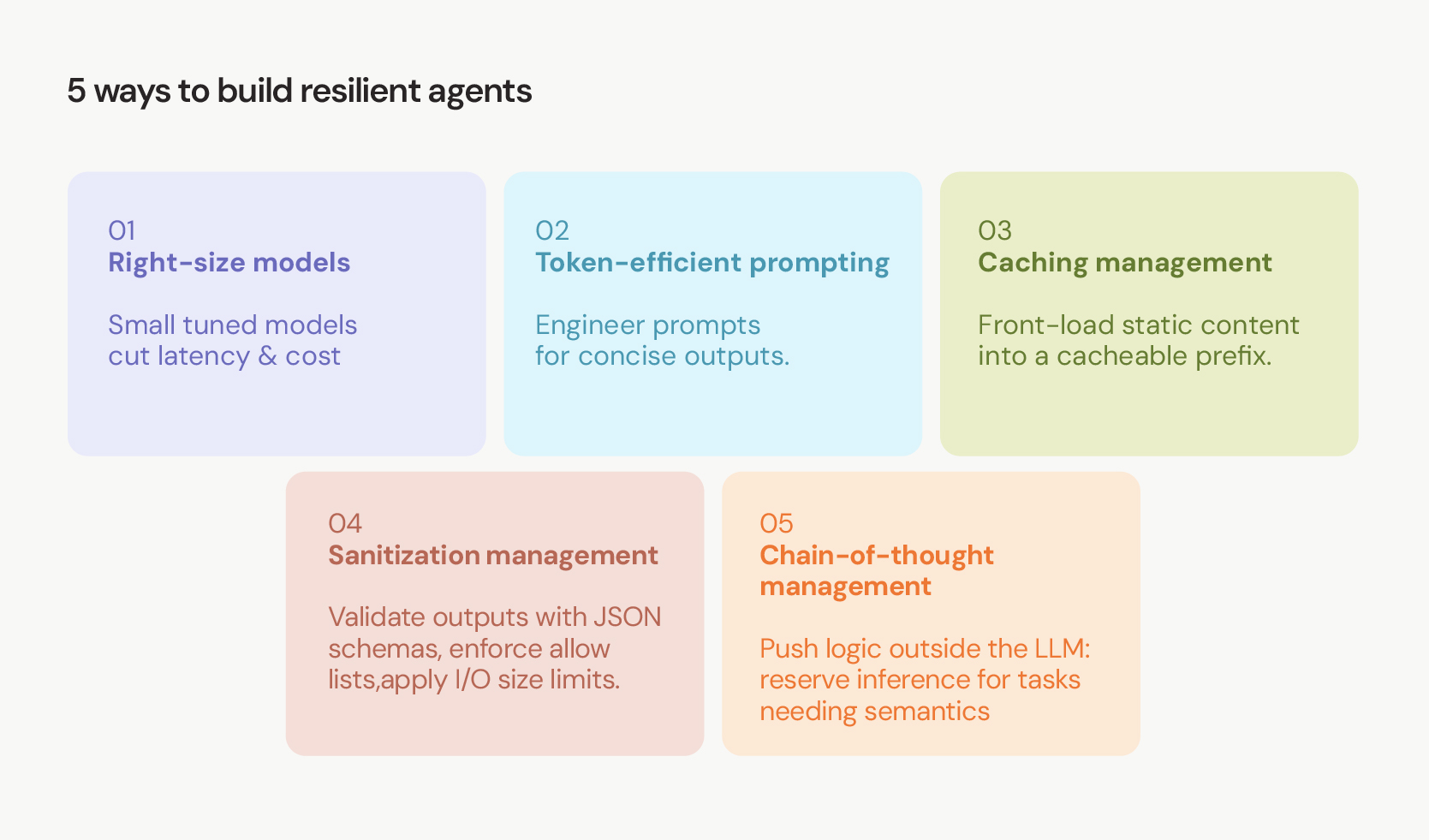
1. Right-size language models (RLMs)
Fundamentally, the industry still pursues trillion-parameter models, but most tasks like routing, classification, extraction, and summarization rarely require such a scale. Smaller, task-specific models, properly tuned, typically reduce latency and resource consumption, often without notable performance loss on target KPIs.
2. Token-efficient prompting
Once the model is properly sized, the next step is to reduce unnecessary token generation. True "macro" Green AI optimization, which is renewable energy and efficient cooling, is managed by cloud providers.
However, we have direct control over how prompts are constructed. Unbounded output generation wastes compute cycles. We can mitigate this by engineering prompts to explicitly request concise outputs. A relevant example is the viral community project "Caveman", which forces AI to output text without grammatical filler.
This project shows that aggressive brevity limitations can yield great reductions in token usage in suitable tasks. Rather than treating such numbers as guarantees, technical leaders should benchmark brevity strategies on their own workloads and report on the actual token and latency savings observed.
3. Caching management
Efficiency also depends on reducing redundant computation across repeated requests. High-throughput agentic loops suffer from massive memory issues if unoptimized. I particularly recommend structuring your requests to use Prompt Caching APIs (like OpenAI's native implementation).
Where available, prompt caching APIs allow you to front-load static content: system prompts, schemas, and tool definitions into a cacheable prefix. Subsequent requests that reuse the same prefix can avoid recomputing input tokens. This can reduce input token cost and improve Time-to-First-Token (TTFT) under supported conditions.
4. Sanitization management
Of course, an efficient system is useless if it isn't secure. When frameworks give an LLM direct access to tools or environments, relying solely on a system prompt to enforce safe behavior is not a good security strategy.
Treat pre- and post-inference sanitization as core requirements: validate outputs with strict JSON schemas, enforce allow lists, and apply input/output size limits. Isolate agent runtimes with dedicated VMs or containers, quotas, and network policies. The Principle of Least Privilege helps ensure sensitive systems remain protected, even if prompts are compromised.
5. Chain-of-thought management
Finally, overusing reasoning-optimized models or chain-of-thought prompts for simple or deterministic tasks is a common source of unnecessary compute consumption. However, not every decision requires probabilistic reasoning.
In many workflows, deterministic rules or heuristics are enough. In those cases, it is often more efficient to implement the logic outside the LLM and reserve inference only for tasks that genuinely require semantic interpretation. This separation keeps marginal inference costs more predictable and makes the overall decision process easier to audit.
The final word: Engineering for the long term
As AI systems mature, efficiency is becoming an engineering discipline in its own right. The conversation around AI is shifting from raw model capability toward disciplined AI engineering.
As frameworks such as the EU AI Act move toward enforcement, organizations will face increasing scrutiny over how AI systems are operated, monitored, and governed, not only what they can generate. For many teams, “Safe & Green AI” becomes a practical engineering goal: building systems that are secure by design, aligned with applicable regulations, and efficient enough to be sustainable at scale.
Ultimately, efficiency is a proxy for architectural quality. By bounding your execution environments, right-sizing your models, and prioritizing deterministic guardrails, you ensure that your AI infrastructure remains viable.
I highly encourage technical leaders to audit current AI pipelines against the OWASP LLM Top 10 and ask themselves: are we building systems we can sustain?
Operationalizing AI agents requires disciplined systems engineering and a clear understanding of infrastructure limitations. As AI systems move from experimentation to operational infrastructure, many teams discover that scaling models is easier than scaling governance, efficiency, and resilience.
Svitla Systems supports clients in assessing current AI pipelines, designing secure and efficient architectures, and implementing managed services that keep operational risk and resource consumption under control.
Whether you need help implementing Managed Services in IT or auditing your cloud deployments, Contact Svitla Systems today to explore how our experts build software that is secure by design and efficient by necessity.

![[Blog cover] Top signs your legacy system needs modernization](https://svitla.com/wp-content/uploads/2025/05/Blog-cover-Top-signs-your-legacy-system-needs-modernization-560x310.jpg)

