
Article summary: Most enterprises are building AI on data that was never prepared for it, and it's the single biggest reason AI projects stall before reaching production. This article covers what AI-ready data means, how to build the strategy and architecture to get there, what that work looks like in healthcare, financial services, and real estate, and how GDPR and the EU AI Act shape the data audit from the start.
Most enterprise data has two jobs: reporting and compliance. Training AI was never one of them. And the governance, if it existed at all, never accounted for the level of detail AI needs.
That mismatch is now impossible to ignore. Over 75% of organizations now rank AI-ready data as a top five investment priority for the next two to three years, according to Gartner's 2024 Evolution of Data Management survey.
AI tooling investment continues to outpace the data foundations those tools depend on. Gartner expects more than 60% of AI projects to fail to meet business SLAs and get abandoned by the end of 2026. A separate forecast finds that 30% of generative AI projects won't survive proof of concept, with poor data quality named as the primary driver.
So, let's explore what AI-ready data is, how to build its strategy and architecture, what it looks like in healthcare and financial services, and how compliance requirements make an impact.
What is AI-ready data?
AI-ready data is data that a machine learning system can learn from and act on for a specific use case, without months of remediation first.
The word doing the heavy lifting there is "specific." According to Gartner, which ranked AI-ready data and AI agents as the two fastest-moving technologies on its 2025 Hype Cycle for AI, readiness should be evaluated against the intended use case and model type.
For example, a dataset that's ready for a fraud detection model can’t be used for a clinical diagnosis tool, even when the underlying data is identical. The model type, the training requirements, and the governance standards all change what "ready" means.
AI-ready data is not high-quality in general, it’s high quality for a specific use case and context.
When analysts prepare data for humans, removing outliers and anomalies is standard practice. Those outliers are noise to a human reader. To a machine learning model, they're often the signal. AI training needs representative data, including errors, outliers, and unexpected but valid records. If you strip those out, the model learns one version of reality, not the full picture.
For example, a fraud detection model trained on idealized transaction data will underperform once fraudulent activity stops following the pattern it learned. Likewise, a medical imaging model trained on perfectly formatted scans will struggle in clinical settings where image quality fluctuates. That gap between curated training data and messy production reality is what affects model accuracy and what sends teams back to the data for months of remediation.
Model accuracy depends on four components working together. Pull any one out and rest degrade.
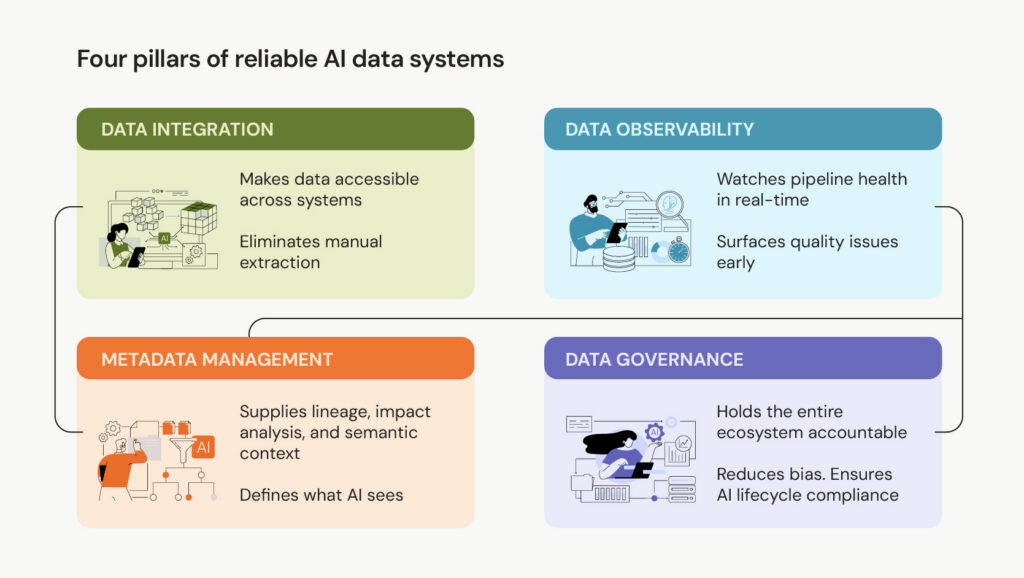
Metadata without governance creates a rich context that nobody owns. Governance without observability leads to policies that look sound on paper but fail in production.
The numbers reflect how common this problem is. Deloitte found that companies are racing to scale AI projects while the data infrastructure underneath them remains unfinished. IBM reports that only 29% of technology leaders believe their enterprise data meets AI's quality, accessibility, and security requirements.
Why do data gaps derail AI projects?
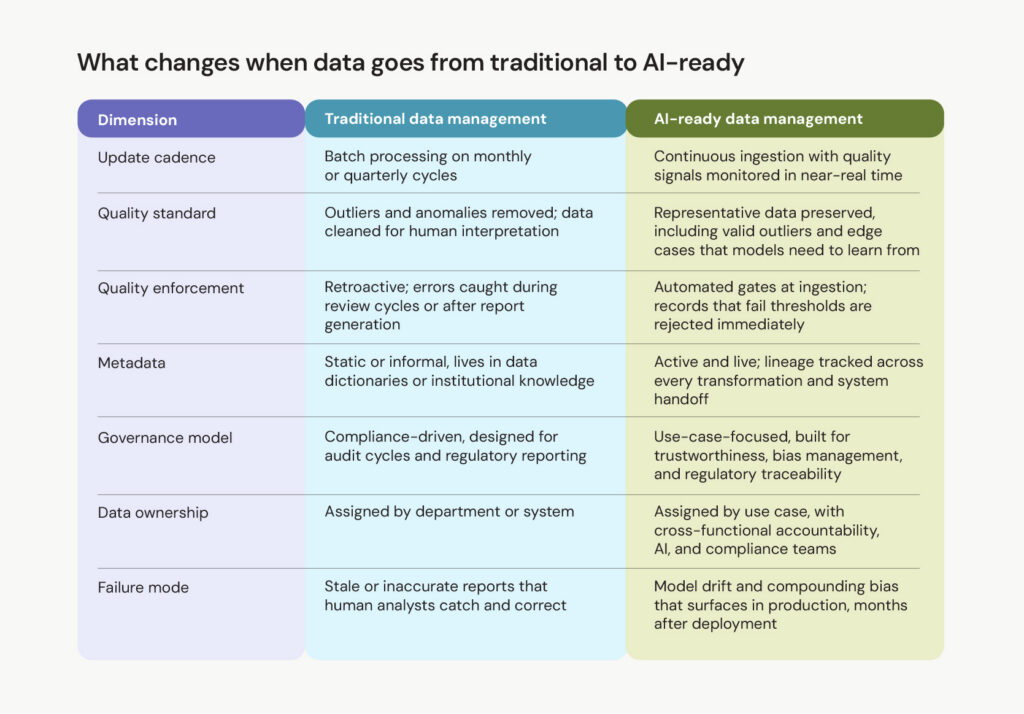
Traditional enterprise data architecture was designed to answer backward-looking questions. What happened last quarter? Which accounts closed last month? How many units were shipped? That meant quality standards were calibrated for human analysts, and governance was built around compliance reporting.
AI needs the reverse: continuous data delivery, quality gates that catch problems in near-real time, and governance granular enough to trace every assumption back to its source.
And ambition is not an issue. Deloitte finds at least 40% of AI adopters still lack mature data practices, with nearly a third of executives naming data problems as a top obstacle. The will is there, but the foundation isn't.
On top of the structural problem, a few specific data gaps appear in nearly every ML project before training even begins.
Data silos
Siloed data forces models to learn from an incomplete picture and make predictions to match. For example, if CRM records don’t connect to billing data, the model sees engagement history but no payment behavior and builds its predictions on half the story. The model can't tell whether it's looking at the same entity twice or two different ones.
Missing history
The missing-history problem usually bites hardest in the use cases that matter most. AI models learn the most from rare events: fraud, equipment failures, customer churn, and clinical deterioration. These events are, by definition, thin on the ground in most enterprise datasets. A model trained on too few examples of these events will have blind spots where it’s expected to perform well.
Audit trails
Without data lineage, there’s no way to trace where a prediction came from or why it went wrong. Every unexplained prediction becomes a liability, whether operationally or regulatory.
That pattern points to something specific about what high-performing AI organizations do differently. McKinsey's 2025 State of AI survey shows that organizations reporting financial returns from AI are nearly three times as likely to have reengineered their business workflows.
Reengineering the workflow is also what produces the documented data lineage, the traceability, and the audit trail that a production model depends on. You don't get those by adding AI on top of an existing process. You get them by rebuilding the process so that the data it generates is governed and traceable from the point of capture.
Johann Beukes, Chief AI Officer at Svitla Systems, observes: "We're treating AI like traditional software, and it isn't."
While traditional software can tolerate imperfect data, AI amplifies even small errors, introducing biases that impact business performance and outcomes.
IDC's 2025 Enterprise AI maturity study found that 84% of organizations have storage and data infrastructure that isn’t ready for AI.
How do you build an AI-ready data strategy?
First, start with the use case. Define what the AI system needs to do, then work backward to identify what the data needs to support it.
Once the use case is identified, the first actionable step is a data audit. Before any pipeline is redesigned or a governance policy is written, the team needs a clear picture of what data exists, where it resides, who owns it, and its current condition.
That means cataloguing every data source connected to the use case and identifying which datasets have usable labels and which need annotation work.
After the audit, the next task is to define requirements tailored to each use case. For example, a dataset structured for fraud detection is often useless for a churn model, even within the same company.
Governance rules, quality thresholds, and pipeline designs must be tied to business goals before making any architectural decisions. This is even harder when visibility is limited: only 23% of organizations have full visibility into their AI training data, according to McKinsey, so most teams design solutions without complete insights.
With requirements in hand, attention turns to building automated quality gates straight into the pipeline. Manual checks don't scale, and they miss drift entirely.
As data volumes climb and models pull in inputs near real time, quality enforcement must happen at ingestion rather than after the fact. The quality problems that blow up in production almost always trace back to a check that wasn't enforced the moment the data came in.
Closely tied to that is active metadata management, which organizations defer most often and regret most consistently. Metadata tells an AI system what it's looking at. Without it, a model can't tell the difference between a field left empty because the value doesn't exist and one left empty because nobody ever collected it.
The market shows how fast becoming AI-ready in data has moved. The data governance market, which counts data lineage tooling as a core component, reached $3.91 billion in 2026 and is on track to hit $9.62 billion by 2030, with a 19.7% annual growth rate largely driven by AI explainability mandates and regulatory pressure. Lineage has gone from a compliance nice-to-have to a foundational requirement for AI readiness, and spending is following suit.
Even so, governance and compliance can't be the thing you bolt on at the end. Any data architecture that touches personal data must incorporate GDPR's Privacy by Design requirement from the start, meaning data protection is built into the pipeline rather than retrofitted after the model is trained. For teams operating under the EU AI Act, that reach extends further still, into documentation, human oversight, and a complete audit trail across the full AI lifecycle.
Building an AI-ready data strategy doesn’t mean starting over. The point isn’t to scrap existing data management and rebuild from zero. Instead, organizations should keep what works and layer AI capabilities on top, use case by use case.
What does AI-ready data look like in healthcare and financial services?
Healthcare and financial services each face the same underlying readiness problem and each faces it differently. Healthcare has enormous volumes of data trapped in disconnected clinical systems. Financial services data is highly structured, but for auditors rather than algorithms. The AI requirements differ from case to case, and so do the paths to preparing the data.
How to make healthcare data AI ready?
Healthcare has more data per patient than in almost any other industry. Unfortunately, most of it can't be used for AI. With enormous volumes of clinical records, imaging files, lab results, billing codes, prescription histories, and more, it’s easy to pinpoint that there’s a fragmentation problem.
Healthcare data usually lives across dozens of disconnected systems within a single institution that were never built to share information with one another, let alone feed a machine learning pipeline.
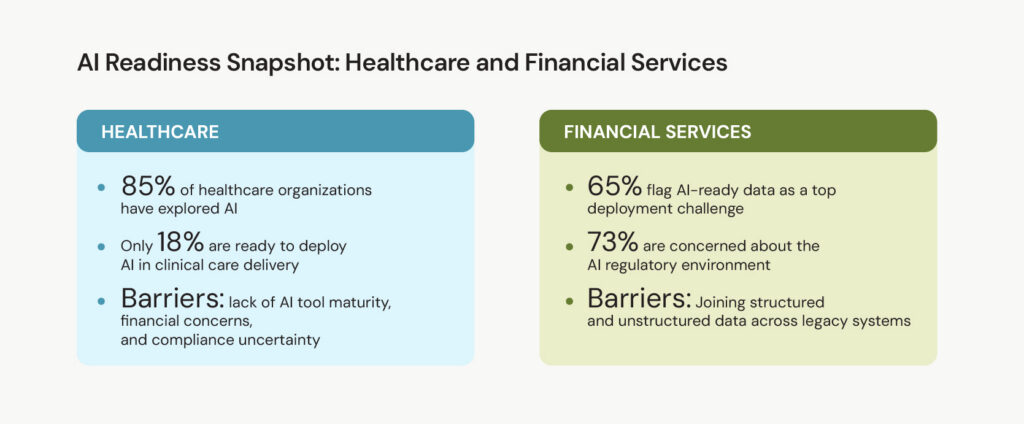
According to HIMSS, 85% of healthcare organizations have explored AI in some form, while only 18% are ready to deploy it in care delivery.
Interoperability sits at the center of it. AI training needs data that can be joined, compared, and queried across clinical encounters. For example, a patient's imaging result sitting in a separate archive, disconnected from their EHR record and lab history, can’t support a clinical model. So, the institutions making progress are the ones that invested in Fast Healthcare Interoperability Resources (FHIR)-enabled pipelines and unified patient data platforms before writing a single line of model code.
Privacy adds a layer of technical precision that most sectors never have to think about. HIPAA compliance for clinical AI means de-identification isn't optional or simple. Standard de-identification can strip out clinically relevant attributes the model needs to learn from, so getting it right means preserving the modeling signal while still satisfying regulators. And the stakes are sky high: IBM's 2025 Cost of a Data Breach report puts the average healthcare breach at $7.42 million, the highest of any sector for the 14th consecutive year.
How to make AI-ready data for financial institutions?
Banks have some of the most structured, well-audited data in the enterprise world. The catch is that it was built for compliance reporting, not for machine learning.
Core banking systems generate clean, well-formatted transaction records that meet regulatory requirements. What they lack is harder to audit: unstructured customer communications, third-party credit signals, and the behavioral indicators a fraud model or churn predictor learns from.
A 2026 study of over 500 global financial institutions found that 65% identify AI-ready data as one of their biggest deployment challenges. A further 73% cite regulatory concerns as a barrier. At the same time, a recent survey of 562 institutions found that AI-enhanced fraud detection cuts both fraud losses and false positives by 40-60% but only for institutions with the data foundation to support it.
The returns come from three things: structuring historical data for AI, documenting its origins, and building models that can explain their reasoning. Regulators require traceable credit and fraud decisions. A model that can’t justify its reasoning is undeployable, regardless of how well it performed in testing.
AI-ready financial data must serve two needs: data scientists require qualitative and transactional information, while compliance teams need audit trails and documentation of bias. The truth is that most current data architectures fail to meet either requirement.
How do data privacy, GDPR, and compliance requirements shape an AI data audit?
Compliance requirements drive data standards, which, when met, incidentally support AI-readiness.
A privacy risk assessment and an AI-ready data architecture require the same groundwork. Getting compliance right produces the kind of documented, traceable, access-controlled data infrastructure that AI systems need anyway. Getting it wrong, or treating it as a final-step audit rather than a design requirement, produces the ad hoc, undocumented data environments that make AI projects fragile and regulators suspicious.
Any organization processing personal data to train or deploy an AI system must establish a lawful basis for that processing under the General Data Protection Regulation (GDPR). While that sounds administrative, the architectural implications are anything but.
The European Data Protection Board's December 2024 opinion clarified something many organizations had assumed they could get around: AI models trained on personal data are not automatically anonymous once training is complete.
The data remains personal, and the organization remains the controller, which means GDPR obligations, including data subject rights, retention limits, and access controls, extend beyond the collection and preparation stages into the post-training phase.
The right to erasure is where the technical reality bites. When a data subject requests the deletion of their personal data, the organization must comply.
But a model trained on that data may have encoded what it learned from that individual into its weights, and "forgetting" what a model learned from one person's data isn't a solved problem in most production environments.
Teams facing this generally do one of three things:
- Implement machine unlearning techniques
- Accept residual risk
- Design training pipelines that minimize the use of directly identifiable personal data from the start.
That last option is both the most practical and the most compatible with AI readiness. It's also what Privacy by Design, under Article 25 of the GDPR, points toward.
Privacy by Design requires data protection to be built into processing systems from the earliest design stages. For AI data pipelines, that means access controls, de-identification, and consent architecture belong in the pipeline specification, not in a retrofit applied after the model is trained.
Data Protection Impact Assessments (DPIA) are mandatory for AI systems that process special categories of personal data or rely on automated decision-making.
A DPIA calls for a documented analysis of the risks to data subject rights, the measures taken to mitigate them, and evidence that those measures were in place before the system went live.
The EU AI Act, in force since 2024, adds a second set of obligations for high-risk AI systems, covering technical documentation, logging, human oversight, and post-market monitoring.
For organizations already operating under GDPR, the documentation requirements from the two frameworks overlap in ways most compliance teams haven't fully mapped yet. The governance infrastructure that satisfies GDPR's audit requirements and the Act's transparency requirements is, in many cases, the same.
The regulatory landscape looks different for organizations operating primarily in the United States. With no federal privacy law equivalent to GDPR, the NIST AI Risk Management Framework has become the closest thing to a binding governance standard, widely adopted across regulated industries and increasingly referenced in state-level AI regulation.
A 2025 Cisco Data Privacy Benchmark Study found that 96% of organizations reported that privacy investments delivered returns greater than their costs.
That figure tends to catch executives off guard, especially those who have classified compliance spending as overhead. What it reflects is the pattern running through this entire topic: the lineage, access control, and documentation infrastructure that compliance requires is the same infrastructure that makes data trustworthy enough for production AI.
Getting the data right is the AI strategy
All costly AI failures share a common cause: the data was never production-ready, even though the model itself was fine.
The path to AI-ready data is specific and repeatable: audit first, use-case alignment second, automated quality enforcement third, active metadata management throughout, and compliance built into the architecture from day one.
The cost of getting that sequence wrong rises as use cases become more impactful.
For example, a fraud model trained on weak data generates false positives and erodes customer trust. A clinical tool trained on fragmented, non-interoperable patient data gives recommendations that clinicians won't act on. An automated valuation model fed inconsistent property records produces numbers that deal teams ignore. These failures weaken the AI-ready business case from the bottom up, even though the model appears to be working.
For years, the competitive question in AI was which model an organization could build or buy. That question is flattening fast because the strongest models become broadly available to everyone at once. What doesn't flatten is the data foundation underneath. Two companies can license the same model.
The one with clean, connected, well-governed data will get materially better results. Organizations that recognize that shift early are building an advantage that their competitors can't simply buy.
Svitla's machine learning and data solutions teams partner closely with clients to deliver reliable data foundations that meet business needs. With deep expertise across the entire data pipeline, they work with clean, connected, well-governed data and ensure strategic alignment for production-scale AI.
FAQ
What is AI-ready data?
AI-ready data is data that a machine learning system can consume directly, in the form its target use case requires, without extensive manual cleaning, relabeling, or restructuring first. Gartner’s operational definition adds useful precision: the data must be aligned with a use case, governed at the asset level, supported by automated pipelines with quality gates, managed through live metadata, and continuously quality-assured.
How do I make my data AI-ready?
Start with an audit: inventory the data that exists, where it lives, who owns it, and its condition across every system feeding the target use case. Define the use-case requirements before touching architecture. Build automated quality gates into the pipeline at ingestion rather than bolting on retroactive checks. Invest in active metadata management early, not once something breaks. And bring governance and compliance into the design from the start. Learn more about Svitla’s AI readiness checklist, which breaks it down step by step.
How do I get my enterprise data ready for AI?
Enterprise readiness must advance on two tracks simultaneously. The technical track means continuous quality pipelines, active metadata management, and documented data lineage across every system feeding the target use case. The organizational track means clear data ownership, quality standards tied to AI objectives, and real cross-functional collaboration among data engineering, AI, legal, and compliance teams.
How do I ensure high-quality data in AI models?
Quality must be enforced at ingestion, meaning automated validation built directly into the pipeline: checks that flag incomplete records, reject inputs that fall below defined thresholds, and route those signals to data stewards through operational dashboards rather than post-incident reviews. Quality that only gets looked at after a model starts behaving strangely is quality that arrived too late. Past ingestion, keeping data quality healthy in production takes active monitoring for drift, the gradual shift in the statistical properties of incoming data that erodes model accuracy without throwing an obvious error. It also requires systematic bias testing, especially in healthcare and financial services, where imbalances in training data directly translate into consequential prediction errors.


